自动驾驶系统卷积神经网络的系统性测试
自动驾驶是应用到CNN的一个新兴领域,基于CNN模型的对象探测器用于识别汽车,行人以及路标。然而对于自动驾驶系统,安全性至关重要,这就需要我们对DNN系统进行安全验证。
研究背景
近年来,卷积神经网络(cnn)成为了在目标分类和检测任务方面取得最新进展的强大模型。它被广泛应用于信息物理系统中。自动驾驶是应用到CNN的一个新兴领域,基于CNN模型的对象探测器用于识别汽车,行人以及路标。然而对于自动驾驶系统,安全性至关重要,这就需要我们对DNN系统进行安全验证。
本文提出了对CNN自动驾驶系统的系统性测试。
解决的问题
自动驾驶系统是基于CNN的极其复杂的系统,此前还没有对于CNN系统的测试验证,本文是验证复杂机器学习组件的首次尝试。
对于CNN系统测试的常见问题是测试集不足,本文提出的图像生成器可以生成大量数据集,增加了测试图像多样性。
实验方法
1. 图像生成器
本文提出的图像生成器呈现道路场景的真实图像。图像是通过排列基本对象(如道路背景、车辆)和调整图像参数(如亮度、对比度、饱和度)得到的。通过保存对象的纵横比,我们生成了更真实的图像。对象和图像参数的所有可能配置都定义了一个修改空间,其元素映射到CNN特征空间的子集(在我们的例子中是道路场景)。本文定义了修改函数,修改函数可用于紧凑地表示特征空间的子集。
例如,给定图片的修改,汽车的位移和亮度,可以看作是二维修改空间的维数。低维修正空间使我们能够在紧凑的区域上分析神经网络,而不是在难以处理的特征空间上分析神经网络。由于本文对汽车上下文中的内容感兴趣,所以考虑改变场景中的颜色对比度以及汽车所在的不同位置。例如,γ(0,0,0)代表在整个场景中较靠近左边,靠近观察者并且图像对比度较高,γ(1,0,0)代表在整个场景中较靠近右边,靠近观察者并且图像对比度较高,γ(1,1,1)代表在整个场景中较靠近右边,远离观察者并且图像对比度较低。
2. 抽样方法
良好的采样技术应能提供对抽象空间的高覆盖率,并能具体识别出会导致图像错误分类的样本。低差序列可以通过减少间隙和点的聚类来覆盖样本空间,低差序列生成的点集可以最小化差异。本文的实验中使用了Halton和基于网格的序列。这些采样方法确保了提取空间的最佳覆盖范围,并允许使用统一的采样技术来识别分类错误的图片集群以及其他难以识别的孤立边缘案例。
在每个步骤中,给定一个样本,利用图像生成器生成图像,这些图像作为被测神经网络的输入。当覆盖输入空间所需的样本数量很大时,这将成为一个昂贵的过程。本文建议使用主动学习来最小化生成的图像的数量,并且只使用样本点,这些样本点具有很高的反例概率。我们将样本空间到CNN分数(输出)的函数建模为高斯过程(GP),高斯过程的框架可以预测任意样本的得分。
3. 可视化工具
在我们的数据分析中,我们考虑了两个因素:置信度评分和交并比(IOU),这是一个用来衡量检测准确度的指标。IOU定义为预测框和地面真实边界框的并集区域上的重叠区域。我们的可视化工具将生成图像的汽车中心与经过处理的CNN.返回的置信度和IOU相关联。本文也提供了将实验数据叠加到渲染图片的背景上的可能性。IOU由标记的维度表示。这种表示有助于我们识别路上的特定兴趣区域。
实验结果
本文在https://github.com/shromonag/farteynn上提供的工具中实现了这个框架。该工具配备了一个由十几个道路背景和汽车模型组成的库。图像库和CNN接口都可以由用户进行个性化设置。作为一个示例研究,本文考虑了一个乡村背景和一辆本田思域,使用渲染技术和Halton采样序列生成了1k合成图像。本文使用生成的图像分析了SqueezeDet(Wu et al., 2016),这是一个用于自动驾驶目标检测的CNN,和Yolo (Redmon et al., 2016),这是一个用于实时检测的多用途CNN。
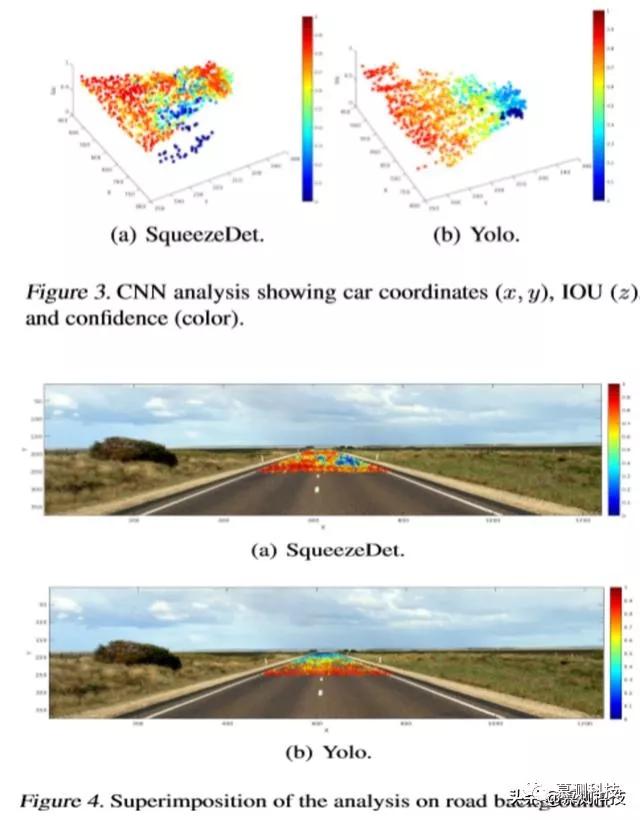
图3显示了与SqueezeDet和Yolo返回的置信度和IOU相关的生成图片的中心。图4将图3的热图叠加在使用的背景上。从获得的图表中,我们可以看到一些有趣的见解(对于背景和汽车模型的组合)。SqueezeDet总体上具有较高的置信度和IOU,但对右侧道路中间的车辆存在盲点(见图3(b)和图4(a)中的蓝点簇)。Yolo s置信度和IOU随着车距的增加而减小(见图3(b))。我们能够检测到Yolo中的一个盲区,对应于最左边的汽车(见图3(b)中的蓝点)。
本文分析如何通过图形化地突出两个cnn在检测、置信度评分和IOU方面的差异,从而在视觉上比较这两个cnn。对这些神经网络的全面分析和比较应该包括结合不同的汽车和背景生成的图像。然而,这个实验已经展示了使用所提供的框架的好处,并强调了即使是简单的研究也可以从CNN中提取出数量和质量的信息。
总结
本文提出了一个系统分析卷积神经网络(CNNs)在自动驾驶系统中的应用框架。该系统化测试应用框架包括一个图像生成器,它通过在低维图像修改子空间中采样生成合成图像,以及一套可视化工具。所提出的框架可以用来提取CNN分类器的洞察力,比较不同的分类模型,或者生成训练和验证数据集。图像生成器通过保存对象的纵横比,调整亮度,对比度,饱和度以及车辆在场景的位置来生成了更真实的图像,生成的图像可用于测试和暴露其漏洞。可视化工具让用户直观的观察到不同场景中改变不同场景要素对于DNN系统的预测影响,有助于研究人员着重考虑一些自动驾驶过程中的敏感区域,从而设计出鲁棒性更强的DNN自动驾驶系统。
思考与未来展望
本文图像生成器生成的图片只是简单的改变了场景要素的位置以及亮度对比度等图像品质,并没有很周到的考虑实际驾驶过程中天气条件的变化,测试集图像的多样性还是比较有限的。
还有个很重要的因素,就是测试图像的真实性,有些极端情况的图像如果数量过多,可能会训练出一个不好的模型,所以我们需要制定一些规则来对测试图像进行输入验证。
智车科技
龚淑娟
李峥
热点文章
-

-

智能网联汽车轨迹优化方法研究综述
2026-07-07
-

看见·增程的“第二生长曲线”
2026-07-14
-

中国企业出海中的人才战略与文化融合
2026-07-07
-

面向ISO 34505的自动驾驶场景评价及测试优先级分析
2026-07-13
-

浅谈智能座舱与人机交互技术创新
2026-07-14
-

连接器如何破局?莫仕携“系统级决绝方案”迈入新阶段
2026-07-08
-
浅谈智能座舱与人机交互技术创新
在汽车电动化、智能化、网联化深度融合的产业趋势下,智能座舱已从配置竞争转向技术体系与落地能力的竞争。本文以零跑汽车为案例,从中央集成电子电气架构、高算力硬件、自研车机操作系统、多模态交互、舱驾融合以及车载大模型六大技术维度,对智能座舱与人机交互关键技术进行深入解析,并聚焦底层技术实现、工程化落地、量产应用效果与成本控制逻辑。研究表明,零跑汽车实现了高阶智能技术的大众化,为自主品牌提供了可复制的实践路径,验证了技术落地成效,并指明了未来优化方向。
作者:
-
看见·增程的“第二生长曲线”
-
面向ISO 34505的自动驾驶场景评价及测试优先级分析
-
国产化替代正当时:永铭车规级固液混合电容,为激光雷达发射端与算力核心提供高纹波耐受解决方案
-
智能网联汽车轨迹优化方法研究综述
-
AI《汽车制造业》增刊





评论
加载更多