高精度地图:自动驾驶的向导
高精度地图是伴随着自动驾驶而生的,是目前研发L3及以上自动驾驶技术的标配。高精度地图是以厘米级精度来描述道路细节的数据集。与传统导航地图不同的是,高精度地图除了能提供的道路(Road)级别的导航信息外,还能够提供车道(Lane)级别的导航信息。无论是在信息的丰富度还是信息的精度方面,都远远高于传统导航地图。
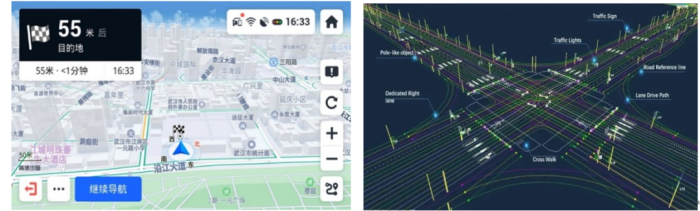
图1 导航地图(左)与高精度地图(右)对比示意图
国内外高精度地图发展概述
高精度地图在自动驾驶中的作用主要体现在如下几个方面:
感知:红绿灯感知、车道线感知、超视距感知等大大简化了自动驾驶过程中后续预测以及规控算法设计的复杂度。
路径规划与决策:使用高精度地图提供的信息提前进行路径规划,同时根据障碍物所在车道位置或者红绿灯等信息预测障碍物可能的运行轨迹,从而提前做出预判和决策。
安全:在雨雪、大雾等极端天气下,各传感器可能会出现一定失效或者感知结果不准确,高精度地图可以有效的进行信息的补充,从而保证自动驾驶汽车行驶过程中的安全性,同时,在一些如多层立交、隧道等复杂的道路场景下,利用高精度地图,结合视觉毫米波雷达、激光雷达等无源定位的无源传感器,实现自主定位,这种融合定位的方式会大大提升定位的准确性,也会进一步提升自动驾驶的安全性。
高精度地图制作方案对比
目前高精度地图的生产制作主要是两种方式,一种是采用摄像头这种纯视觉的生产方式,代表的公司Deep Motion、宽凳科技、Momenta等初创公司,纯视觉的生产方式除了大大降低生产成本,还会使得高精度地图制作的周期大大降低,加速高精度地图众包方案的落地,但是对算法技术的创新有较高的要求。另一种主流的方案是采用以激光雷达为主的高精地图采集方案来进行高精度地图的生产(图2为高精度地图采集车示意图以及实物图),代表公司有很多,例如Waymo、百度、四维图新、高德等,采用激光雷达为主,摄像头为辅的方案相对来说技术比较成熟,可以综合利用各个传感器的优势进行算法的研发,简化了后续算法研发的复杂度。但是生产制作成本高,生产周期长,同时不利于众包更新高精度地图方案的落地。
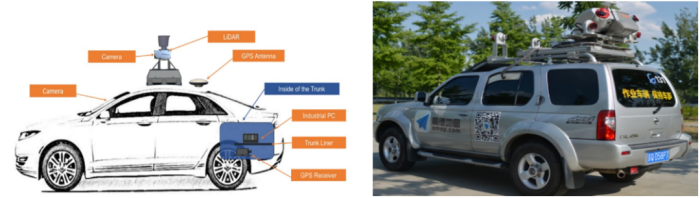
图2 高精度地图采集车示意图与实物图(从左到右)
高精度地图制作技术发展趋势
高精度地图可以分为两个层级:静态高精度地图和动态高精度地图。受限于芯片算力以及制作成本的考虑,目前的高精度地图制作都是围绕静态高精度地图展开的,其组成主要包括车道线信息、方向箭头信息、道路标志牌信息、道路属性信息等。在静态高精度地图图层之上,动态高精度地图主要包括道路上发生的实时动态信息,主要包括随时间变化的交通标志(如红绿灯状态、潮汐车道等)、道路交通信息(道路拥堵情况、事故发生情况、道路施工情况、交通管制情况、天气情况、路面积水情况等)。目前高精度地图的生成一般涉及到的技术为数据采集、栅格图预处理、数据标注、检测识别、自动矢量化等生产流程,如图3所示。

图3 高精度地图生产流程
数据采集技术:一般利用多传感器GPS、IMU、轮速计、激光雷达或者摄像头融合技术计算出当前采集车的位置信息,将该位置信息以及激光雷达/摄像头的扫描信息写入到地图数据中。
栅格图预处理:这里主要涉及点云拼接、栅格图融合以及伪影去除等。
数据标注:利用标注工具对需要识别的元素按照一定的规则进行标注。
检测识别:这里主要是利用深度学习算法进行检测和识别,提供目标元素的语义以及位置信息。
自动矢量化:按照一定的精度要求,给出利用点线以及多边形所描述目标物体的坐标信息。这里主要涉及数据采样、多边形拟合等传统图像数据处理算法。
可以看出整个流程还是相当繁琐的,同时制作成本也是相当高的。加上后期的地图更新和维护成本也会是相当复杂和价格高昂,这些都大大限制了其使用范围,尤其是在自动驾驶领域大规模的落地使用和更新。
因此,为了解决在自动驾驶技术落地高精度地图使用的问题,产生了实时局部高精度地图生成的技术路线。相比较传统的高精度地图生成,该技术路线主要体现在高精度地图生成的实时性以及空间范围的局部性(只产生处在当前车辆周边环境的高精度地图信息以供自动驾驶使用)两个方面,如图4所示。
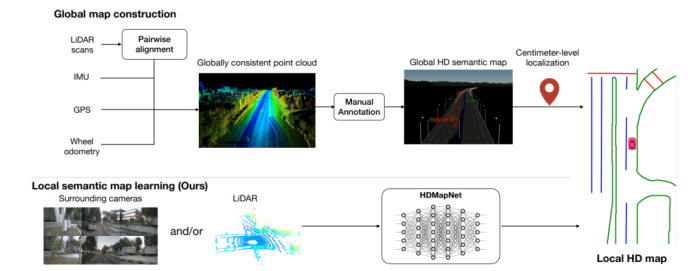
图4 传统高精度地图生产与实时局部高精度地图生产方式对比
2021年,实时局部高精度地图技术路线主要是利用多视图摄像头/激光雷达采集到的图像数据利用神经网络进行特征提取并利用相机外参投影到鸟瞰图视角下,在鸟瞰图视角下进行解码操作得到车道线的分割信息以及车道线方向信息,在经过后处理操作得到矢量地图,如图5所示。
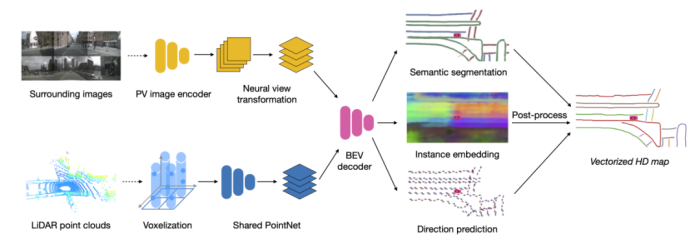
图5 在线局部高精度地图生成模型
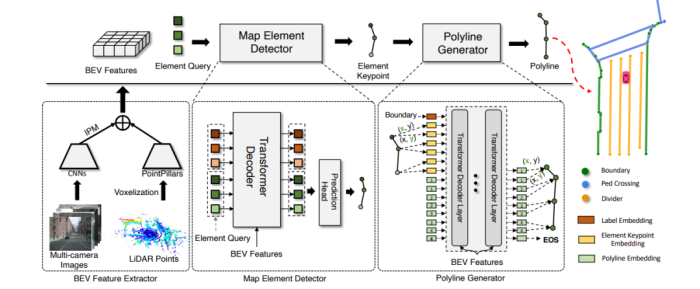
图6 VectorMapNet网络结构图
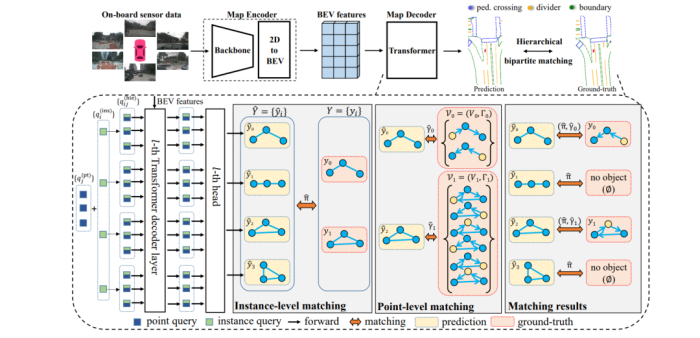
图7 MapTR网络结构图
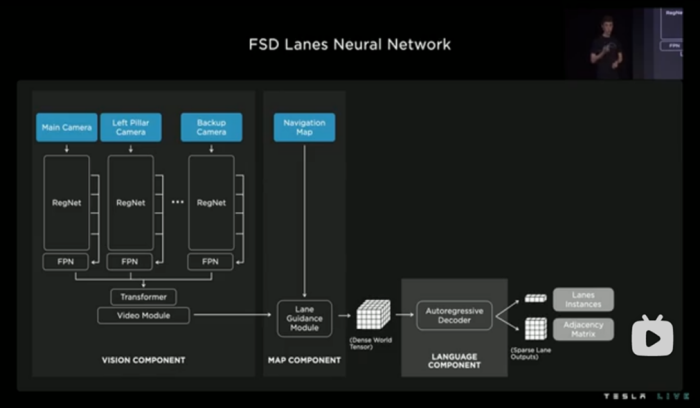
图8 Lanes Neural Network网络结构图
高精度地图制作技术发展趋势
从目前的技术发展路线来看,未来自动驾驶所需的高精度地图使用方式无论从制作成本、使用的便利性以后续更新的实时性角度考虑,很大概率会使用这种局部实时构建高精度地图的方式,感知数据输入会分为纯视觉(多视图)以及视觉与激光雷达融合输入的方案,但都是在鸟瞰图视角下利用transformer网络结构对多源数据(摄像头、激光雷达)进行感知特征的统一表征,同时为了提高车道线关键点之间拓扑结构关系描述的准确性以及更多的高精度地图元素输出,带有地图文本描述的信息会越来越多的加入到网络结构中,利用transformer网络结构将这些特征信息进行交互得到更准确的位置信息以及更多的高精度地图元素输出,而不局限于只有车道线、人行横道线等有关高精度地图线信息元素的矢量化输出。通过将视觉感知、文本、语音等不同模态数据,通过映射到同一语义空间进行特征对齐后,利用transformer网络结构进行特征交互学习得到统一的多模态特征,灵活的根据不同的下游任务进行特征解码操作也将是未来很多AI模型训练的一种方式。
焉知智能汽车
龚淑娟
李峥
热点文章
-

智能汽车场景化开发:系统融合与 用户体验的协同研究
2026-07-20
-

“泰钽”来了!开启智能越野3.0时代
2026-07-22
-

基于传动效率的多模复合功率分流混合动力系统模式控制研究
2026-07-21
-

乘用车混合动力总成系统设计和性能仿真研究
2026-07-22
-

动力系统主导车市质变,增程器迈入系统竞争
2026-07-23
-

基于深度学习的电驱实验系统设计
2026-07-24
-

-
基于深度学习的电驱实验系统设计
针对传统永磁同步电机建模方法难以兼顾精度与实时性的问题,本文基于深度学习技术提出一种融合物理约束的永磁同步电机降阶模型,通过深度神经网络实现对电机非线性电磁特性的精细化建模。围绕所提降阶模型,搭建了电驱实验系统,并将该模型集成至电驱系统中,实现了实时硬件在环验证。在不同工况下对降阶模型和传统dq轴解析模型开展实验分析,结果表明,所提出的基于深度学习的永磁同步电机降阶模型在保证高精度建模的同时,实现了更好的动态性能。该模型支撑的实验系统可用于电驱系统的快速仿真与控制算法研究,具有良好的工程应用前景。
作者:
-
动力系统主导车市质变,增程器迈入系统竞争
-
“泰钽”来了!开启智能越野3.0时代
-
乘用车混合动力总成系统设计和性能仿真研究
-
基于传动效率的多模复合功率分流混合动力系统模式控制研究
-
智能汽车场景化开发:系统融合与 用户体验的协同研究





评论
加载更多