基于深度学习的人脸检测和识别方法介绍
文章来源:知乎
发布时间:2020-02-13
人脸识别分人脸验证(face verification)和人脸确认(face identification)。前者是指两个人是不是同一个人,即1-to-1 mapping,而后者是确定一个人是一群人中的某个,即1-to-many mapping。
人脸识别分人脸验证(face verification)和人脸确认(face identification)。前者是指两个人是不是同一个人,即1-to-1 mapping,而后者是确定一个人是一群人中的某个,即1-to-many mapping。
人脸作为一种特殊的目标,如同人体(行人检测)一样,前面讨论的目标检测/识别算法可以直接采用,但也会有其特殊的设计考虑,比如其刚体(rigid body)特征和特有的人脸模版(由眼睛、鼻子和嘴巴等显著部分构成)。
一个完整的人脸识别系统包括人脸的检测、校准和分类三部分,下面分别讨论深度学习的应用方法。
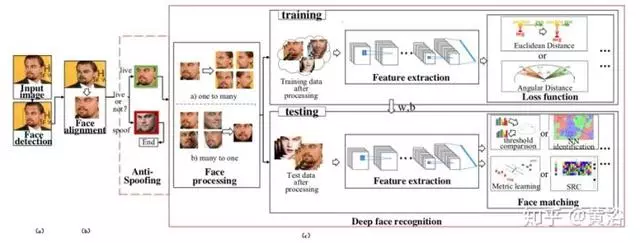
如图所示,(a)使用面部检测来定位面部;
(b)与归一化规范坐标对齐;
(c)实施FR。
在FR模块中,面部反欺骗(anti-spoofing)可判断面部是否有效或有欺骗性; 在训练和测试之前面部处理降低识别难度; 在训练时,使用不同的网络结构和损失函数来提取深层特征; 当提取测试数据的深层特征时,面部匹配进行特征分类。
人脸检测大致分为两种方案:
一是刚性模板(rigid templates)法,主要通过基于增强的方法(boosting based methods)或深度学习神经网络,二是通过部件描述面部的可变形模型(deformable models)。
这里以RetinaFace为例介绍一下基于深度学习的算法。
RetinaFace是一个单步人脸检测器,利用联合监督和自我监督的多任务学习,在各种尺度人脸图像上执行逐像素的人脸定位。
当在WIDER FACE数据集上手动标注五个面部关键点(眼角,嘴角和鼻子顶部)之后,借助这个额外的监督信号,比较难的人面检测例子性能上显著改进。
添加一个自监督网格解码器分支(mesh decoder branch),包括网格卷积和上采样,并与监督分支并行地预测逐像素的三维形状面部信息。
下图是该方法的直观图,每个正样本锚框定输出(1)面部得分,(2)面部框,(3)五个面部关键点,(4)投影在图像平面上的密集面部3D模型顶点。
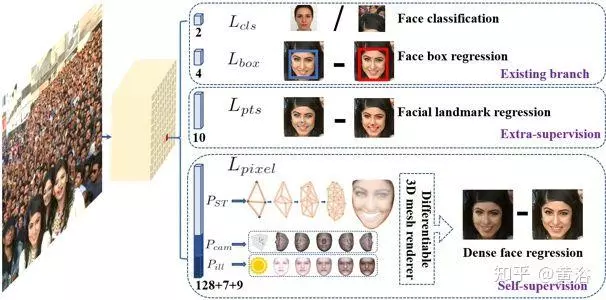
如图是单步密集人脸定位方法。
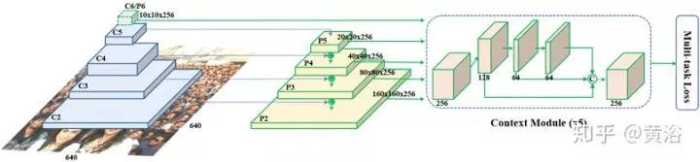
RetinaFace设计的思想来自于具有独立上下文模块的特征金字塔。
在上下文模块之后,计算每个锚框的多任务损失函数。
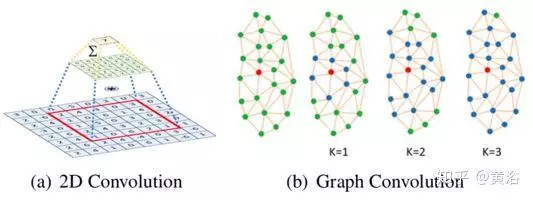
网格解码器是基于快速局部谱滤波(spectral filter)的图卷积(graph convolution)方法。
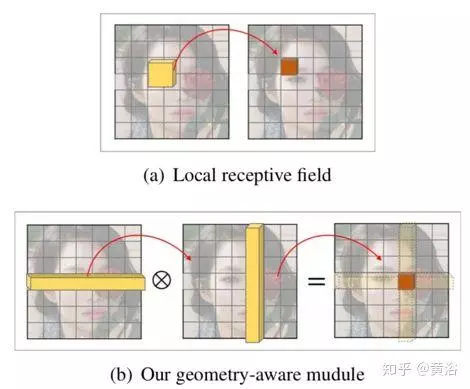
如图所示,(a)2D卷积是欧几里德网格感受域(receptive field)内的邻域核加权和。
(b)图卷积也采用邻域核加权和的形式,但以连接两个顶点的最小边数来计算邻域距离。
具有内核gθ的图卷积可以表示为截断K阶的递归Chebyshev多项式,即
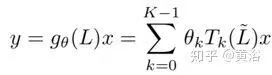
在预测形状和纹理参数之后,采用一种有效的可微分3D网格渲染器,基于相机参数(即相机位置、相机姿势和焦距)和照明参数(即位置 点光源,颜色值和环境照明的颜色)将图像网格投影2D图像平面上。
一旦得到渲染的2D面部图像,采用以下函数比较渲染和原始2D面部的像素差异作为损失:
校准(alignment)需要人脸关键点(facial landmarks)的检测。
面部关键点检测算法分为三大类:
整体(holistic)方法,约束局部模型(CLM)方法和基于回归的方法。
整体方法明确地建立模型以代表全局面部外观和形状信息。
CLM明确利用全局形状模型,但构建局部外观模型(local appearance models)。基于回归的方法隐含地捕获面部形状和外观信息。
下面讨论基于深度学习的人脸关键点检测算法。
在早期的工作中,深度玻尔兹曼机器模型(DBM)作为概率深度模型,捕获面部形状变化。
最近,CNN模型成为典型关键点检测的主导模型,其中大多数遵循全球(global)直接回归框架或级联(cascaded)回归框架。
这些方法可以广泛地分为纯学习(pure learning)方法和混合(hybrid)法。
纯学习方法直接预测面部关键点位置,而混合法结合深度学习方法和计算机视觉投影模型进行预测。
以下以ODN为例介绍深度学习的关键点检测具体方法。
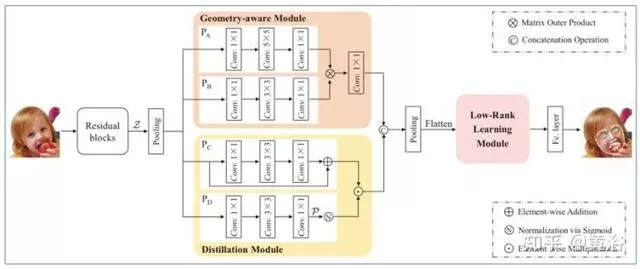
遮挡自适应深度网络(ODN,Occlusion-Adaptive Deep Networks),旨在解决面部关键点检测的遮挡问题。
在该模型中,高层特征在每个位置的遮挡概率由一个可以自动学习面部外观和面部形状之间关系的蒸馏模块(distillation module)推断。
遮挡概率当作高层特征的自适应权重,减少遮挡的影响并获得清晰的特征表示。
由于缺少语义特征,干净的特征表示不能代表整体(holistic)面部。
要获得详尽而完整的特征表示,必须利用低阶(low-rank)学习模块来恢复丢失的特征。
面部几何特征有助于低阶模块重新覆盖丢失的特征,ODN提出了一种几何觉察模块来挖掘不同面部组件之间的几何关系。
如图所示,ODN框架主要由三个紧密结合的模块组成:
几何觉察模块,蒸馏模块和低阶学习模块。
首先,先前残差学习块的特征图Z输入到几何觉察模块和蒸馏模块中,分别捕获几何信息并获得干净的特征表示。
然后,组合这两个模块的输出作为低阶学习模块的输入,对面部的特征相关性建模来恢复缺失的特征。
下图是几何觉察模块的结构图,比较局部感受野和几何觉察模块如何捕捉面部几何关系。
⊗表示矩阵外积(outer product)。
从ODN框架图可见,低阶学习模块主要是学习共享结构矩阵,该矩阵对特征间/属性相关性明确编码,以便恢复缺失的特征并去除冗余特征。
自2014年以来,深度学习重塑了人脸识别(FR)的研究领域,最早的突破从Deepface方法开始。
从那时起,深度FR技术利用分层架构将像素拼接成具有不变性的面部表示,极大地改善了性能并促进实际产品成功。
在深度学习的人脸识别系统中,损失函数分为几种:
基于欧几里德距离、基于角/余弦余量和softmax等。
基于深度学习的面部图像处理方法(例如姿势变化)分为两类:
““一对多增强(one-to- many augmentation)”型和“多对一归一化(many-to-one normalization)”型。
训练深度学习模型进行人脸识别有两个主要研究方向:
1)有些人训练了一个多类别分类器,在训练集中分离不同个体,例如使用softmax分类器,2)直接学习嵌入关系,例如三体损失(Triplet Loss)。
对于softmax的损失:
线性变换矩阵大小随着个体数而线性增加,学习的特征对于闭集分类问题是可分离的,但对于开集人脸识别问题则不具有足够判别能力。
而对于三体的损失:面部三体的数量存在组合爆炸,特别是对于大规模数据集,导致迭代步数显着增加;另外,半难度样本的挖掘是有效模型训练中一个相当难的问题。
这里以ArcFace为例介绍具体的深度学习人脸识别算法。
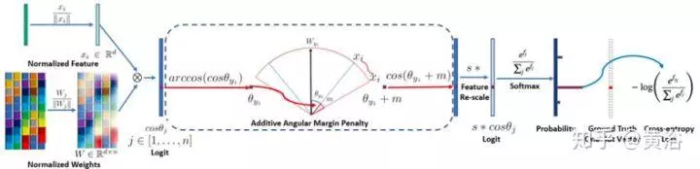
如图是ArcFace如何识别人脸的框架。
DCNN特征与最后一个全连接层之间的点积等于特征和权重归一化后的余弦距离。
利用反余弦函数计算当前特征与目标权重之间的角度。
然后,在目标角度添加一个附加角度边缘(additive angular margin),再通过余弦函数再次得到目标逻辑模型。
这样通过固定的特征规范重新尺度化所有逻辑模型,那么以后的步骤与softmax损失完全相同。
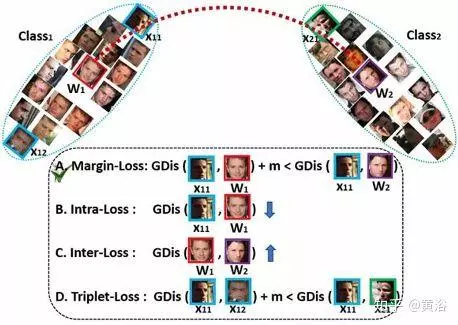
如图是ArcFace各种损失函数的对比。
基于中心和特征归一化,所有个体都分布在超球面上。
为了增强类内紧凑性和类间差异,考虑四种测地距离(Geodesic Distance,GDis)约束。
(a)边缘化损失(Margin Loss):
在样本和中心之间插入测地距离边界。
(b)类内损失:
减少样本与相应中心之间的测地距离。
(c)类间损失:增加不同中心之间的测地距离。
(d)三体(Triplet)损失:
在三体样本之间插入测地距离边界。
这里是一个ArcFace提出的附加角度边缘化损失(Additive Angular Margin Loss),它与(a)中的测地距离(Arc)边界罚分完全对应,以增强人脸识别模型的判别力。
1.S Zafeiriou,C Zhang,Z Zhang,“A Survey on Face Detection in the wild:past,present and future”,CVIU,2015
2.J Deng et al.,“RetinaFace:Single-stage Dense Face Localisation in the Wild”,arXiv 1905.00641,2019
3.M Wang,W Deng,“Deep face recognition:survey”,arXiv 1804.06655,2018
4.J Deng et al.“ArcFace:Additive Angular Margin Loss for Deep Face Recognition”.CVPR 2019
5.Y Wu,Q Ji,“Facial Landmark Detection:a Literature Survey”,arXiv 1805.05563,2018
6.M Zhu et al.“Robust Facial Landmark Detection via Occlusion-Adaptive Deep Networks”,CVPR 2019













获取更多评论