谷歌再获语音识别新进展:利用序列转导来实现多人语音识别和说话人分类
从 WaveNet 到 Tacotron,再到 RNN-T,谷歌一直站在语音人工智能技术的最前沿。近日,他们又将多人语音识别和说话人分类问题融合在了同一个网络模型中,在模型性能上取得了重大的突破。
对于自动理解人类音频的任务来说,识别「谁说了什么」(或称「说话人分类」)是一个关键的步骤。例如,在一段医生和患者的对话中,医生问:「你按时服用心脏病药物了吗?」患者回答道:「Yes」。这与医生反问患者「Yes?」的意义是有本质区别的。
传统的说话人分类(speaker diarization,SD)系统有两个步骤。在第一步中,系统将检测声谱中的变化,从而确定在一段对话中,说话人什么时候改变了;在第二步中,系统将识别出整段对话中的各个说话人。这种基础的多步方法[1]几乎已经被使用了 20 多年,而在么长的时间内,研究者们仅仅在「说话人变化检测」部分提升了模型性能。
近年来,随着一种名为递归神经网络变换器(RNN-T)[2]的新型神经网络模型的发展,我们现在拥有了一种合适的架构,它可以克服之前我们介绍过的说话人分类系统[3]的局限性,提升系统的性能。在谷歌最近发布的论文「Joint Speech Recognition and Speaker Diarization via Sequence Transduction」[4]中,它们提出了一种基于 RNN-T 的说话人分类系统,证明了该系统在单词分类误差率从 20 % 降低到了 2%(性能提升了 10 倍),该工作将在 Interspeech 2019 上展示。
传统的说话人分类系统
传统的说话人分类系统依赖于人声的声学差异识别出对话中不同的说话人。根据男人和女人的音高,仅仅使用简单的声学模型(例如,混合高斯模型),就可以在一步中相对容易地将他们区分开来。然而,想要区分出音高可能相近的说话者,说话者分类系统就需要使用多步方法了。首先,基于检测到的人声特征,使用一个变化检测算法将对话切分成均匀的片段,我们希望每段仅仅包含一个说话人。接着,使用一个深度学习模型将上述说话人的声音片段映射到一个嵌入向量上。最后,在聚类阶段,会对上述嵌入聚类在不同的簇中,追踪对话中的同一个说话人。
在真实场景下,说话人分类系统与声学语音识别(ASR)系统会并行化运行,这两个系统的输出将会被结合,从而为识别出的单词分配标签。
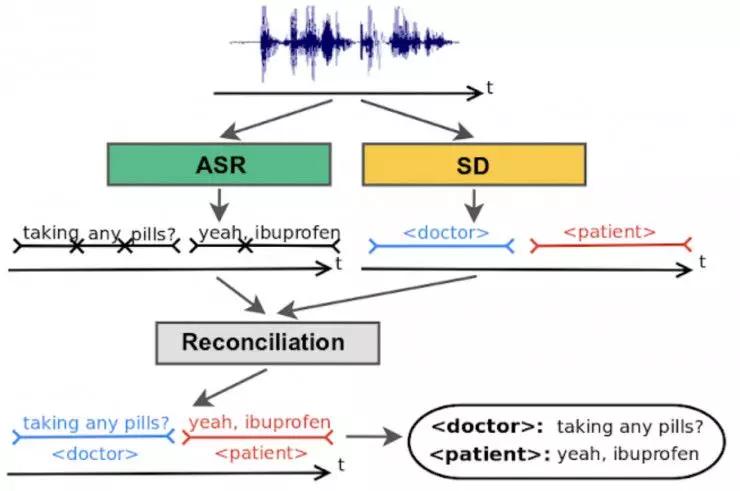
传统的说话人分类系统在声学域中进行推断,然后将说话人标签覆盖在由独立的 ASR 系统生成的单词上。
这种方法存在很多不足,阻碍了该领域的发展:
(1)我们需要将对话切分成仅仅包含以为说话人的语音的片段。否则,根据这些片段生成的嵌入就不能准确地表征说话人的声学特征。然而,实际上,这里用到的变化检测算法并不是十全十美的,会导致分割出的片段可能包含多位说话人的语音。
(2)聚类阶段要求说话人的数量已知,并且这一阶段对于输入的准确性十分敏感。
(3)系统需要在用于估计人声特征的片段大小和期望的模型准确率之间做出艰难的权衡。片段越长,人声特征的质量就越高,因为此时模型拥有更多关于说话人的信息。这然而,这就带来了将较短的插入语分配给错误的说话人的风险。这将产生非常严重的后果,例如,在处理临床医学或金融领域的对话的环境下,我们需要准确地追踪肯定和否定的陈述。
(4)传统的说话人分类系统并没有一套方便的机制,从而利用在许多自然对话中非常明显的语言学线索。例如,「你多久服一次药?」在临床对话中最有可能是医护人员说的,而不会是病人说的。类似地,「我们应该什么时候上交作业?」则最有可能是学生说的,而不是老师说的。语言学的线索也标志着说话人有很高的概率发生了改变(例如,在一个问句之后)。
然而,传统的说话人分类系统也有一些性能较好的例子,在谷歌此前发布的一篇博文中就介绍了其中之一[5]。在此工作中,循环神经网络(RNN)的隐藏状态会追踪说话人,克服了聚类阶段的缺点。而本文提出的模型则采用了不容的方法,引入了语言学线索。
集成的语音识别和说话人分类系统
我们研发出了一种简单的新型模型,该模型不仅完美地融合了声学和语音线索,而且将说话人分类和语音识别任务融合在了同一个系统中。相较于相同环境下仅仅进行语音识别的系统相比,这个集成模型并没有显著降低语音识别性能。
我们意识到,很关键的一点是:RNN-T 架构非常适用于集成声学和语言学线索。RNN-T 模型由三个不同的网络组成:(1)转录网络(或称编码器),将声帧映射到一个潜在表征上。(2)预测网络,在给定先前的目标标签的情况下,预测下一个目标标签。(3)级联网络,融合上述两个网络的输出,并在该时间步生成这组输出标签的概率分布。
请注意,在下图所示的架构中存在一个反馈循环,其中先前识别出的单词会被作为输入返回给模型,这使得 RNN-T 模型能够引入语言学线索(例如,问题的结尾)。
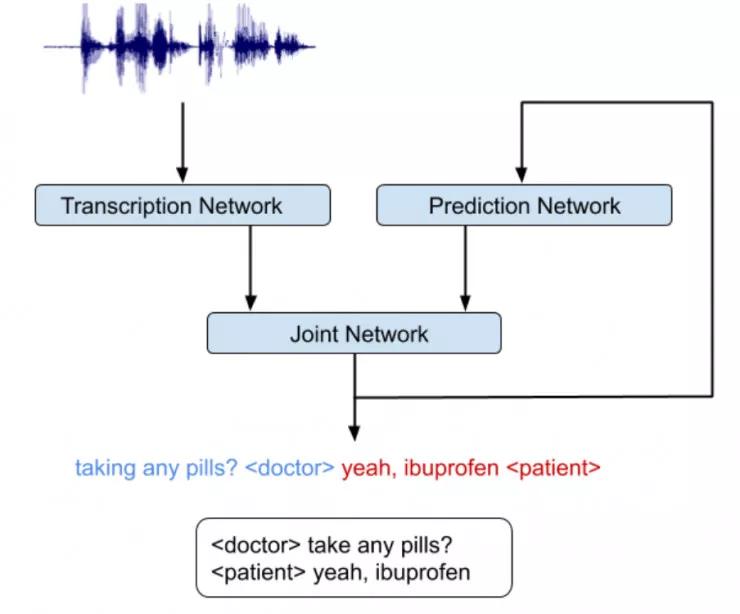
集成的语音识别和说话人分类系统示意图,该系统同时推断「谁,在何时,说了什么」
在图形处理单元(GPU)或张量处理单元(TPU)这样的加速器上训练 RNN-T 并不是一件容易的事,这是因为损失函数的计算需要运行「前向推导-反向传播」算法,该过程涉及到所有可能的输入和输出序列的对齐。最近,该问题在一种对 TPU 友好的「前向-后向」算法中得到了解决,它将该问题重新定义为一个矩阵乘法的序列。我们还利用了TensorFlow 平台中的一个高效的 RNN-T 损失的实现,这使得模型开发可以迅速地进行迭代,从而训练了一个非常深的网络。
这个集成模型可以直接像一个语音识别模型一样训练。训练使用的参考译文包含说话人所说的单词,以及紧随其后的指定说话人角色的标签。例如,「作业的截止日期是什么时候?」<学生>,「我希望你们在明天上课之前上交作业」<老师>。当模型根据音频和相应的参考译文样本训练好之后,用户可以输入对话记录,然后得到形式相似的输出结果。我们的分析说明,RNN-T 系统上的改进会影响到所有类型的误差率(包括较快的说话者转换,单词边界的切分,在存在语音覆盖的情况下错误的说话者对齐,以及较差的音频质量)。此外,相较于传统的系统,RNN-T 系统展现出了一致的性能,以每段对话的平均误差作为评价指标时,方差有明显的降低。
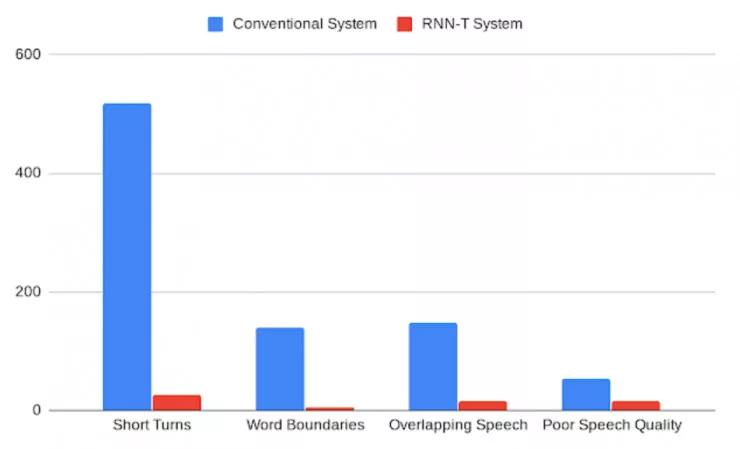
传统系统和 RNN-T 系统错误率的对比,由人类标注者进行分类。
此外,该集成模型还可以预测其它一些标签,这些标签对于生成对读者更加友好的 ASR 译文是必需的。例如,我们已经可以使用匹配好的训练数据,通过标点符号和大小写标志,提升译文质量。相较于我们之前的模型(单独训练,并作为一个 ASR 的后处理步骤),我们的输出在标点符号和大小写上的误差更小。
现在,该模型已经成为了我们理解医疗对话的项目[6]中的一个标准模块,并且可以在我们的非医疗语音服务中被广泛采用。
Via https://ai.googleblog.com/2019/08/joint-speech-recognition-and-speaker.html
参考资料:
[1] https://ieeexplore.ieee.org/document/1202280/
[2] https://arxiv.org/abs/1211.3711
[3] https://ai.googleblog.com/2018/11/accurate-online-speaker-diarization.html
[4] https://arxiv.org/abs/1907.05337
[5] https://ai.googleblog.com/2018/11/accurate-online-speaker-diarization.html
[6] https://ai.googleblog.com/2017/11/understanding-medical-conversations.html











![]()
2001-2009 Vogel Industry Media版权所有 京ICP备12020067号-15 京公网安备110102001177号


获取更多评论