
自动驾驶多传感器融合技术浅析
自动驾驶车上使用了多种多样的传感器,不同类型的传感器间在功用上互相补充,提高自动驾驶系统的安全系数。为了发挥不同传感器优势,融合技术起着关键的作用,现对多传感器融合技术(指前融合)按照下图方式进行分类。
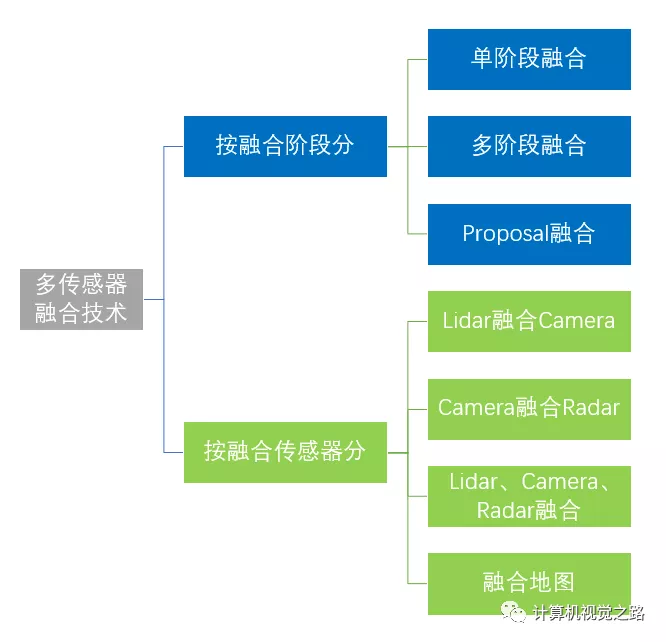
-
单阶段融合: 指在整个融合算法流程的数据阶段或者cnn网络中某一个特征提取层进行相关数据或者特征的融合,代表有:PointPainting[1],LaserNet++[2] -
多阶段融合: 指在整个融合算法流程的不同特征提取层进行特征融合,代表有:ContFusion[3] -
Proposal融合: 这种融合方式一般在多阶段的检测方法中使用,使用第一阶段proposal得到的候选框,在目标框级别进行相关传感器的特征融合。代表有:AVOD[4],F-PointNets[5],MV3D[6]
按照融合传感器的分类方式相对好理解,比较常见的是Lidar与Camera的融合,当然车上的任何一个传感器理论上都可以融合使用,后面再详细介绍。
单阶段融合
这种融合算法最容易理解,也最容易实现。下面用PointPainting[1]和LaserNet++[2]为例说明。
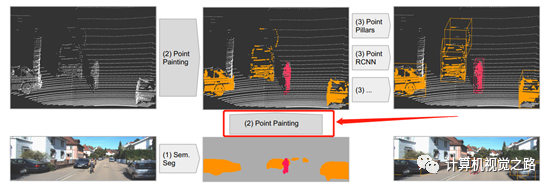
整个算法流程如上图所示,在融合网络结构设计上并非end-to-end训练方式,分成了2个阶段,第一阶段,对camera数据做语义分割,第二阶段,将激光雷达点云与语义信息相结合做3D目标检测。通过特征投影将两个阶段联系起来,也就是图中的第二步:Point Painting。
这个投影过程也分为两步,首先在源数据上建立点云与图像像素间的对应关系,这个对应关系可以通过多传感器的标定参数计算得到:P(camera)=K*T*P(lidar),其中K为相机的内参,T为lidar到camera的标定参数,如下式,由于不同传感器获得数据是有一些时间差,通过自车的定位信息做出补偿即可。第二步则在此对应关系的基础上,将语义分割网络的输出与点云特征concatenate,得到3D目标检测网络的输入。
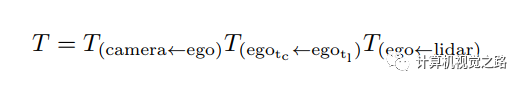
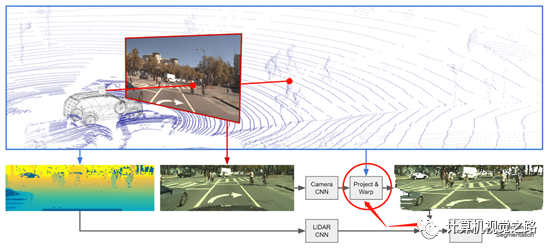
LaserNet++[2]设计了一个end-to-end的融合网络,如上图所示,分别用两个网络来提取camera数据与lidar点云的特征,然后通过特征投影,将两种特征通过相加的方式组合成新的特征,再使用lasernet[7]完成3D目标检测。
投影过程也是分为两步,首先在源数据上建立camera/range view图像与图像像素的对应关系,然后再利用对应关系得到两种传感器相对应的特征。Lasernet++[2]在做点云特征提取时,使用了camera/rang view的表达方式,因此,建立点云与图像像素对应关系也分为两步:
计算点云与range view图像的对应关系,如下式,其中p为点云坐标,
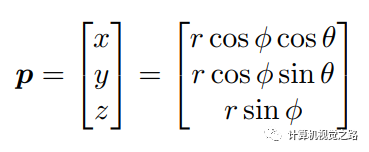
2)计算点云与图像像素的对应关系,如下式,其中(u,v)为图像坐标,p为点云坐标,K为相机内参,R和t为从lidar坐标到camera坐标变换的旋转矩阵和平移矩阵。
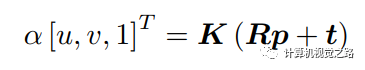
大家可以发现单阶段融合都是从源数据出发建立不同传感器的数据对应关系,然后在特征级别融合。为什么说这个方法相对简单,因为这种数据对应关系最少是单向一一对应,如稀疏点云的点可以一一对应到图像的像素点上,因此在做特征融合时不需要很复杂的处理,仅使用数据这种单向一一对应关系便可以融合。
多阶段融合
多阶段融合方法以ContFusion[3]为例,相对单阶段融合,这种方法会复杂一些,主要复杂在融合特征的提取上。
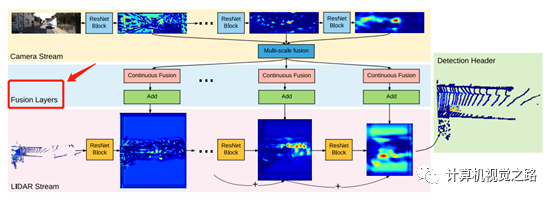
整体网络结构如上图所示,比较清晰,是一个end-to-end网络,分成了4个部分:camera特征提取(黄色区域)、特征融合(蓝色区域)、lidar特征提取(粉色区域)、检测输出(浅绿色区域)。这种设计的好处就是可以dense的融合两种信息,但是问题也很明显,效率不怎么高。
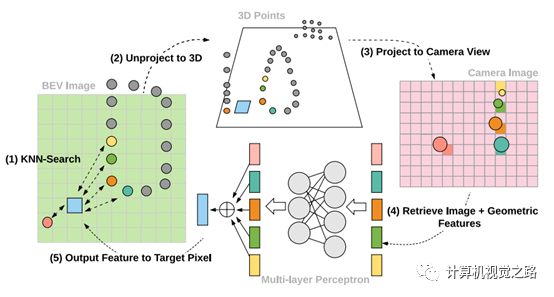
这个投影关系的建立整体上来说分成2大步:建立源数据投影关系、提取融合特征。具体如上图所示分成了5步:
-
作者在lidar特征提取时使用了bev表达,我们知道bev上的像素点与点云并不是一一对应的,bev图是很稀疏的,因此作者使用了KNN的方式,获得bev图上每一个像素对应的K个点云 -
将bev图下得到的k个最近邻的点反投影回点云坐标 -
建立点云点与图像像素的对应关系,建立方式和单阶段融合的方式相同 -
由于lidar点投影到图像素坐标为浮点数,因此需要通过插值得到投影点的特征向量 -
通过mlp得到图像特征与几何特征的融合特征,计算方式如下式所示,其中fj为j点的图像特征,x为点云3D坐标,xj-xi为j点与目标点i点距离差。最后hi与lidar点云特征相加得到最终的融合特征。
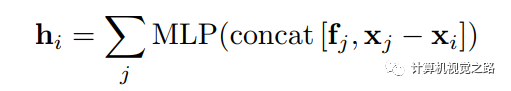
ContFusion[3]融合方式中KNN的参数选取很关键,k值和d值对最终结果影响较大,k和d都不易太大,太大会融合远处点云点的信息,干扰当前点的特征表达,模型效果变差。Continuous convolution[8]增加了整个模型的复杂度。
Proposal融合
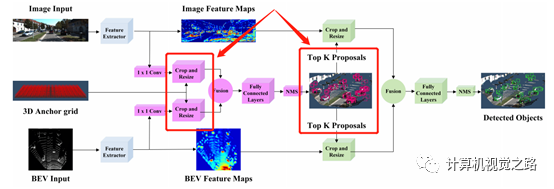
这种融合方法主要出现在多阶段检测方法中,在投影方面不再涉及源数据投影,或者特征投影,涉及的是3D框的投影;网络结构设计上,使用常见的two-stage detector的设计方式,这里不做重点介绍。另外这种融合方式有点儿像后融合,如果设计的网络结构不是end-to-end训练方式,也可以作为后融合方法,如F-PointNets[5],这里不介绍后融合方法。AVOD[4]是在MV3D[6]的基础上提出的,框的投影方式是类似的。下面根据MV3D[6]对框的投影方式介绍一下:
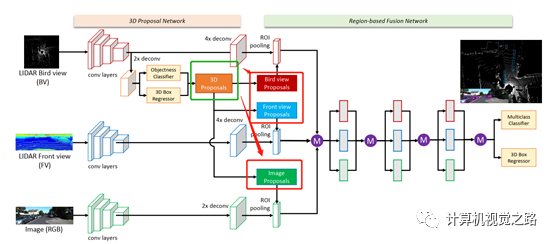
如上图所示,为MV3D[6]的网络结构,其中3D proposal由bev网络得到,然后将其分别投影到不同的特征表达图上:bev,range view,camera,计算方式如下式,然后在不同传感器的特征图上roi align得到不同的特征并融合在一起。
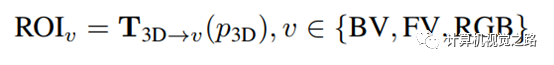
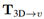 是3D框到不同特征表达图v的投影。
是3D框到不同特征表达图v的投影。
对于AVOD[4]来说,框的投影有两次,如下图所示,一次是使用3D anchor,avod在提取proposal时,仅对含有点云的anchor单独判断是否有目标,在这个地方与常见的two-stage detector不同;第二次是proposal,即3D候选框.。
总结
以上针对融合阶段这种分类方式对多传感器融合技术做了简单的分析,重点分析了多传感器融合技术中的两个核心问题:数据/特征投影,融合网络设计。
-
投影方式 决定了融合算法能否end-to-end训练,而end-to-end训练能使模型得到更好的结果,如在PointPainting方法中,作者认为由于PointPainting[1]没有使用end-to-end训练,会造成该方法无法得到最好的结果。 -
对于融合网络设计,主要考虑融合特征的提取,或融合方式的设计,是数据/单层特征融合,还是多层特征融合,还是目标级特征融合?正如MV3D[6]中讨论的early fusion、deep fusion、late fusion:deep fusion相对另外两种融合方式在精度上可以提高0.5个百分点,但是在实际应用时,还需要考虑speed vs accuracy平衡的问题。
另外,以上融合方法都是Lidar与Camera的融合,其他传感的融合方法后面会继续介绍。
参考文献
PointPainting: Sequential Fusion for 3D Object Detection
Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation
Deep Continuous Fusion for Multi-Sensor 3D Object Detection
Joint 3D Proposal Generation and Object Detection from View
AggregationFrustum PointNets for 3D Object Detection from RGB-D Data
Multi-View 3D Object Detection Network for Autonomous Driving
LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
Deep Parametric Continuous Convolutional Neural Networks





![]()
2001-2009 Vogel Industry Media版权所有 京ICP备12020067号-15 京公网安备110102001177号


正在获取数据......