你真的了解什么是智能座舱么(域控制器篇)
文章来源:阿宝1990
发布时间:2020-11-03
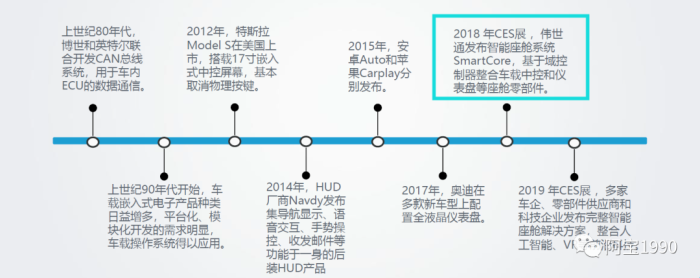
智能座舱发展经历了整体基础 智能座舱发展经历了整体基础 -细分产品 细分产品 -融合方案的格局变化。先是整体电子器架构和操作系统出现,随后各细分产品逐渐装载到车上,如今的趋势是各产品的协同整合。
要说奥迪A4L凭什么这么受欢迎,能够在销量上领先奔驰和宝马,我觉得“科
技”是非常重要的一点,这也是奥迪品牌一向的标签,像是仪表盘这项汽车上古时代的配置,奥迪就重新将其定义,打造出了“
虚拟座舱
”,带给了用户革命性的
创新体验。
每一位奥迪A4L的用户,无不称赞其虚拟座舱带来的科技与便利性。
而近日上市的全新奥迪A4L也不出所望,再次将“创新科技”四个字诠释的淋漓尽致。
看看媒体都是怎么评论的,这次奥迪A4L就带来了最新一代MMI系统,该系统可以说是目前最好用的车机系统之一。因为它完全符合中国消费者的使用习惯,要知道,与其他操作系统依据国外使用习惯不同,最新一代的MMI信息娱乐系统是基于安卓平台开发,并专为中国用户打造的应用体系,值得一提的是,这也首款引入安卓平台的豪华品牌车型。安卓平台最大的优点就是“开放”性,这意味着奥迪A4L的车机系统,不再像其他车型的车机一样,局限于仅有的几个功能,而是可以根据用户的使用需求,自主下载,选择APP。
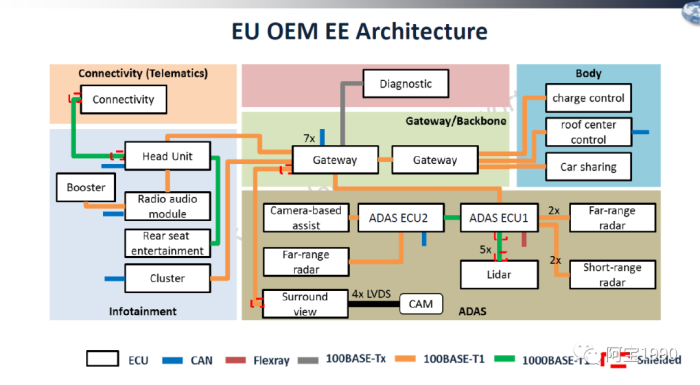
而这里的全新奥迪A4L的智能座舱使用的就是高通820A芯片做的域控制器,简单来说就是一颗主芯片既输出给中控导航,又输出液晶仪表信息,而且两个产品在同一个芯片上跑不同的软件系统,那我们来唠嗑一下什么是域控制器。
一
智能座舱发展经历了整体基础 智能座舱发展经历了整体基础 -细分产品 细分产品 -融合方案的格局变化。
先是整体电子器架构和操作系统出现,随后各细分产品逐渐装载到车上,如今的趋势是各产品的协同整合。
可以看到2018年伟世通才出现基于座舱产品的域控制器,主要是整合了车载中控和仪表,还没有整合更多的ADAS功能的产品,比如360环视、LDWS等功能进去,说明这个域控制器有一定的难度。
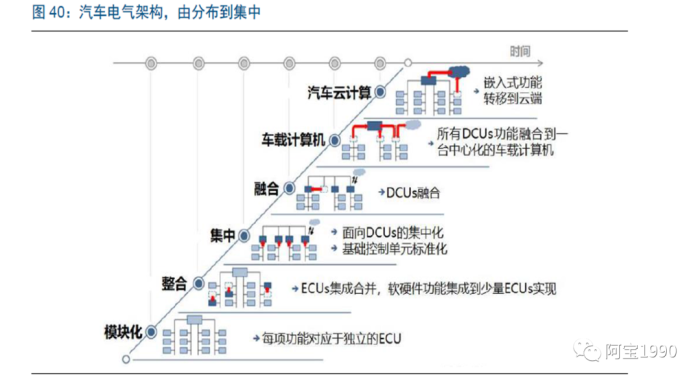
博世将整车电子电气架构发展分为6 个阶段:模块化阶段、功能集成阶段、中央域控制器阶段、跨域融合阶段、车载中央电脑和区域控制器阶段、车载云计算阶段,目前大多数整车厂商开始从模块化向功能集成阶段迈进,而特斯拉已经达到了第五个车载中央电脑和区域控制器阶段。目前汽车的电气架构绝大部分都是处于第一阶段,模块化的阶段。
随着汽车工业的飞速发展,汽车电子电气系统变得十分复杂,一辆普通汽车的电子控制单元(ECU)已经多达70-80 个,代码约一亿行,且各个ECU 往往来源于供应链中不同的tier1,有着不同的嵌入式软件和底层逻辑,各个ECU 往往独立运行,整车厂没有权限也没有能力维护更新ECU,因此传统汽车的软件更新几乎与汽车生命周期同步,整车企业以OTA 方式更新软件系统受限,目前仅仅局限于娱乐信息系统更新。
传统座 舱,仪表、娱乐、中控等系统相互独立,主要由单一芯片驱动单个功能/系统,通信开销大,就比如中控和仪表间进行地图的通讯,传统座舱需要增加2个LVDS芯片+2个LVDS座子+高速信号线材,既增加了通讯的成本,而且通讯时间也增加了。
一芯多屏”模式采用一颗芯片支持多个操作系统,不仅解决了系统之间高成本的 通信开销问题,同时缩短了通信时间,而且减少了单个AP及外围的成本,随着量产数量的增加,不断降低域控制器的芯片成本。
1、新能源汽车以及动力电池技术发展迅猛。车身电子电器架构正在进行深度升级,由传统的分布式向中心演变,不同操作系统之间通过虚拟机打;同时三元锂离子电池能量密度已经突破300wh/kg,为智能座舱各功提供能量基础。
在新能源车的发展过程中你会看到很多同传统车不一样的先进技术在这方面使用,由于新能源车本身的架构和传统燃油就有很大的不同,对比于燃油车,新能源汽车的结构更简单。
目前的燃油车结构比新能源汽车更复杂,特别是动力总成系统部分,要比新能源汽车复杂得多。新能源汽车的车辆结构较为简单,主要部件为动力电池组、电机和EMS组成的三电系统,因此在新能源汽车上开发或者使用自动驾驶技术,那么出现概率的情况要比燃油车低得多。与此同时,从操控上来说,新能源汽车也要比燃油车更好操控——控制电压电流的大小以及输出,远比控制传统内燃机来得容易得多。
所以比如一些ADAS的设备、TBOX、以太网、还有一些域控制器都是在优先在新能源车上出现,然后逐步使用到燃油车上。
2、芯片的运算能力呈指数级提升,可以满足一些域控制器的基本硬件条件,甚至可以满足自动驾驶的算力要求,各大芯片厂商都推出了算力匹配的主控芯片,同时自动驾驶的技术成熟使得人们从驾驶场景解放出来,更多的注意力放在智能座舱场景里面去,所以这方面的芯片的推动也是巨大的。
3、云计算和5G的铺设速度加快,云平台的计算、存储能力和5G的传输速度为智能座舱的预控器的大数据量、低延迟需求提供了保障。
从分布式到集中式,域控制以及未来计算平台将成为智能驾驶最大的增量。过去汽车的控制器主要以分布式为主,每个控制器针对一个功能。随着汽车智能化等级的提升,原本的多个控制器将集成为域控制。
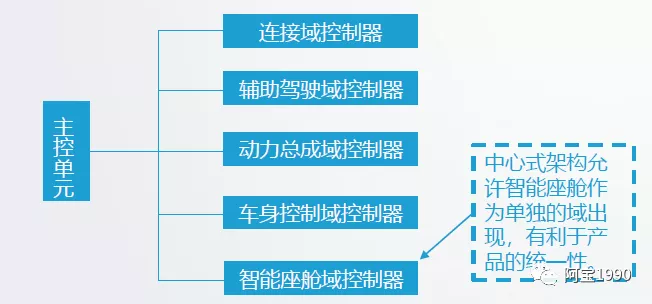
车内电子架构将来会划分为5个域:
驾驶辅助/自动驾驶域、智能座舱控制域、车身控制域、车身控制域、动力总成域。
而其中驾驶辅助/自动驾驶域、智能座舱域为汽车未来核心,也是未来车企差异化竞争,实现软硬件分离从而实现软件盈利的关键核心点。
二
域控制器阶段是以以太网为骨干网,面向服务的架构,按功能划分的集中化可以加速软硬件分离,节约整机的成本,具体的优点如下:
a.减少内部算力的冗余,避免ECU数量膨胀,减少设计算力总需求;
b.传统分布式架构难以实现实时交互,集中式架构可以统一交互,并实现整车功能协同;
a.分布式架构软硬一体,整车企业并没有权限去维护和更新ECU,因此无法通过后续OTA更新解决问题。变成集中式架构后,软硬解耦,可以通过系统升级(OTA)持续地改进车辆功能,软件一定程度上实现了传统4S店的功能,可以持续地为提供车辆交付后的运营和服务;
b.整体形成感知层后,采集的数据信息可共用。软硬解耦后,可实现多个应用共用一套硬件装置,有效减少硬件数量。
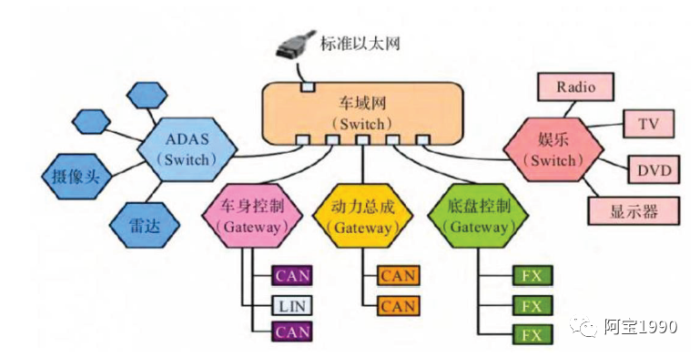
3)通信架构升级。采用高速以太网取代CAN总线,为未来汽车添加更多车联网、ADAS功能提供支撑。
a.高实时性:数十微秒的确定性传输延迟和亚微秒级的节点时间同步精度
b.高带宽:百倍传输,满足大量非结构化数据(视频、图片)的传输
三
a.传统的汽车芯片厂家遇到消费领域巨头芯片厂家的挑战
根据专业调查数据,在2015年以前都是以瑞萨、NXP、TI等传统汽车芯片主导市场,前面三家的芯片就占据市场60%的份额,从2015年开始,越来越多的消费级芯片巨头参与汽车芯片生产商重组并购。
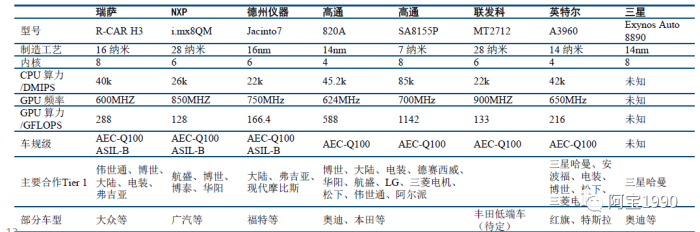
智能座舱域控制器芯片 市场的主要参与者包括 NXP、德州仪器、瑞萨电子等传统汽车芯片厂商,主要面向中低 端市场,此外手机领域的厂商如联发科、三星、高通等也加入市场竞争中,主要面向高端市场,这个市场越来越好看,越来越好玩。
由于域控制器芯片市场仍处于行业萌芽期
,目前国内搭载座舱域控制器芯片的 车型绝大部分仍然采用的是德州仪器的Jacinto6 和 NXP 的 i.mx6 等上一代产品。国内竞 争者主要有华为、地平线等。根据伟世通数据,2019 年全球座舱域控制器出货量约为 40 万套,预计 2025 年出货量将超过 1300 万套,2019-2025 年均增长 79%。
b. 相对于消费级芯,车规级芯片对于可靠性、安全性的要求更高
从上图可以看到,车规级芯片在温度、湿度、碰撞等多个维度范围更宽,需要承受的极限条件更苛刻,此外,由于开发需求的复杂化,在芯片设计、测试等环节投入更高的成本和时间,所以在市场中可以看到车机芯片的更新换代速度相对较慢(有的车型一卖就是七八年),车机芯片升级的动力不足,态度更加谨慎,这两年车机芯片的运行速度已经和消费级芯片大幅缩小了。
汽车座舱领域迭代速度也开始像手机一样快速,产品的生命周期越来越短,竞争越来越激烈,原本手机领域的厂家如联发科、三星、高通都加入阵营,未来华为还有紫光展锐也会加入。手机领域的厂家主要着眼点在于研发成果的最大限度利用。而原本传统的汽车SoC芯片厂家NXP、瑞萨和德州仪器压力大增。
智能座舱芯片:高端以高通、英特尔、瑞萨为主(还要看其第四代产品竞争力),高通领先
CPU性能对比:高通820A CPU性能与英特尔、瑞萨基本一致。但8155具备全方面的性能优势,8.5万DMIPS同代产品领先。
GPU性能:目前浮点性能上,高通相比于瑞萨、英特尔领先较多,比如820A的GPU性能为588GFLOPS,而英特尔为216GFLOPS,瑞萨为115.2GFLOPS。
中低端玩家:恩智浦(i.MX6/i.MX8)、德州仪器(Jacinto 6/ Jacinto 8);
英特尔在2015年将Atom系列拓展到汽车领域,即Apollo Lake,也就是3900系列,2017年为强化低端市场,特别推出低价位的A3920,其性能实际与3900系列旗舰A3960相差不多,但价格是3900系列中最低的。价格低,但性能丝毫不低,不过截止2019年7月,A3920还未通过AEC-Q100认证,这是基础的车规级认证,但这并不影响其市场,目前已经有车厂在导入A3920。
特斯拉为A3950做了活广告。国内红旗和长城也开始采用英特尔的SoC,国际上则有宝马和沃尔沃两大客户。英特尔的强大支撑还有开源的ACRN虚拟机,这是其他厂家望尘莫及的。其他家的虚拟机方案一般只能选择Xen或收费的QNX,目前英特尔最新的车规级AEC-Q100芯片是A3960,这个还在推广中。
联发科也以高性价比的MT2712主打市场,目前已通过伟世通打入大众供应链,可能会用在下一代帕萨特上。也有消息说可能上到丰田的低端车上,伟世通的主打平台就是联发科和高通。
NXP的i.mx系列曾经是中控领域的霸主,不过高通未能成行的收购打乱了NXP的节奏,导致NXP的产品跳票多次,也缺乏高端产品。NXP的i.mx8QM一波三折,跳票了多次,不过目前已经基本解决问题。
不过NXP为了稳定客户,已经向大客户宣传更高端的i.mx8.5和i.mx10x系列产品了,具体情况未公开,可能也有采用A76和A55,但是估计最快也要到2021年底才有样片。
德州仪器对嵌入式处理器领域似乎越来越不感兴趣,因为模拟器件钱太好赚了,一个产品可以卖上30 甚至40 年。德州仪器的Jacinto7 系列一直未公开, 目前已知最接近的是DRA804M 和TDA4V,前者采用4核A53,主要做汽车网关,后者则针对汽车视觉处理,特别是AVP,有2-4核的A72,考虑到TDA产品线和座舱的Jacinto产品线重合度高,推测Jacinto7应该接近TDA4V。和i.mx8QM一样都采取硬件隔离的形式,做虚拟机时可以省掉不少软件研发费用。德州仪器跟奥迪、大众合作紧密,预计下一代奥迪或大众会有车型使用Jacinto7。在国内,德州仪器主要合作伙伴是德赛西威。
瑞萨的R-CAR H3也经历一波三折,多次推迟量产。这款芯片在2015年12月首次推出,在当时是相当先进的芯片,但在4年后,虽然仍然不落伍,但考虑到它高昂的售价,性价比明显是偏低了,不过H3是唯一一个在推出之时就通过高等级的ASIL-B级认证的。瑞萨跟日系车合作非常紧密,通常都是和整车厂一起开发芯片,丰田毫无疑问会使用瑞萨的R-CAR H3系列产品。
实际上,在国内市场都是高端车型,绝大部分车型中控和仪表仍然是德州仪器的Jacinto6和NXP的i.mx6,域控制器的芯片就已经城头变换大王旗喽。
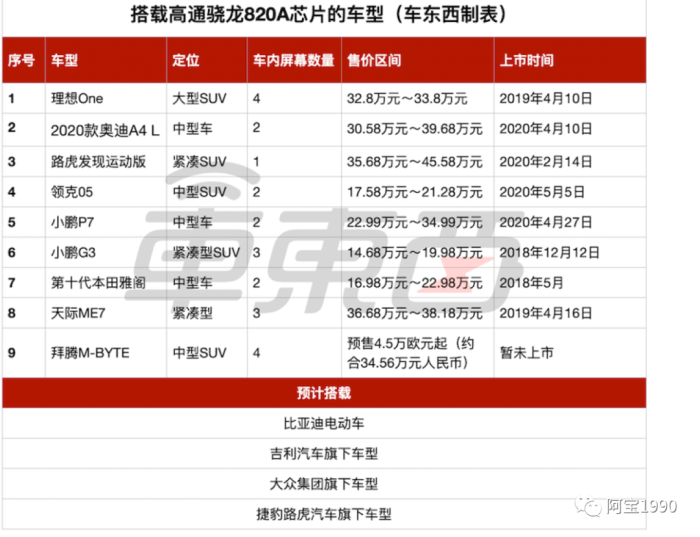
4月10日,中期改款的奥迪A4 L上市,这款车在外观和动力部分没太多的改动,不过车机系统的变化却很明显。中控娱乐屏幕从此前的非触控屏升级为触控屏,车机芯片从骁龙602A升级为骁龙820A,系统也换成了安卓Pie(安卓9)。这里不能跟手机比,手机都到安卓11了,以前手机在安卓9的时候,车机系统还是安卓4.4左右。得益于车机的安卓系统,奥迪A4 L可以在车机内安装导航、天气、音乐等第三方应用程序,较此前奥迪的MMI系统可谓是产生了质的变化。
不过,在软件背后还有更厉害的高通骁龙820A,正是这颗芯片的加入,让车机能够流畅运行安卓系统和各种应用。820A是高通此前在移动设备上的旗舰芯片骁龙820的车规版本。
汽车智能化浪潮兴起以来,高通、英特尔、英伟达等企业,就一直希望以高算力芯片为核心,以车机系统和自动驾驶为突破点,切入汽车半导体市场。但在过去几年里,这些玩家的动作往往是雷声大雨点小——签约合作站台不少,实际落地的品牌一两个,车型若干台,并不成气候。
高通于2014推出了第一代智能座舱SOC是602A车机芯片,虽然早在2014年就跟奥迪等车企签署了合作,但是一直都是雷声大雨点小,实际落地车型寥寥无几,几乎没有什么反应。
在2016年把手机领域的820没做太多修改,推广到汽车领域,型号变为820a,a就代表汽车版。现阶段新出的车型内部屏幕是越来越大,越来越多,清晰度也是越来越高,甚至可以说就是在车内装了几个平板电脑,原来就是旗舰级移动设备芯片的骁龙820A,自然是目前车企可选择的最强产品。
但到了2020年,最终在经过四五年的等待之后,820A芯片终于迎来一波爆发。高通820A却借着奥迪A4L、领克05、小鹏P7,还有去年上市的理想ONE等热门车型,一下成了行业热词、旗舰标配。
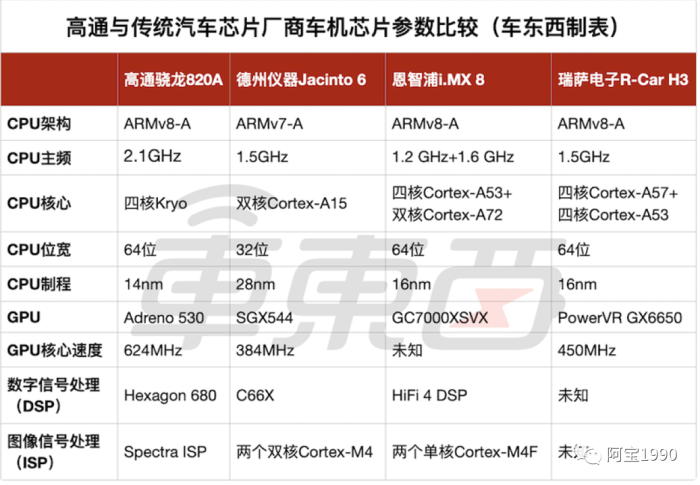
上表是高通820A与几个老玩家的王牌车机芯片对比表,可以非常直观地看到性能差距。
从制程上来说,恩智浦i.MX8、瑞萨的H3都落后于高通820A的16nm,德仪的J6甚至还用的是28nm的老技术。要知道,目前消费电子领域的芯片制程已经在普及7nm,甚至向着5nm前进了。CPU主频也是如此,除了820A,其它三个产品的主频都是2GHz以下,性能上自然落了下风。
在图形处理器(GPU)方面,骁龙820A采用Adreno 530 GPU,核心速度为624MHz,14nm制程,在四款芯片中处理性能排名第一。瑞萨电子的R-Car H3采用PowerVR GX6650 GPU排名第二,核心速度450MHz,采用28nm的制程。
德州仪器Jacinto 6采用SGX544 GPU,核心速度为384MHz,采用45nm制程,图形处理性能排名第三。恩智浦的i.MX 8采用GC 7000XSVX GPU,根据Notebook Check网站公布的数据,这颗GPU的处理性能和Adreno 305相近,性能比瑞萨电子和德州仪器的芯片都要弱。CPU的性能直接决定了车机在处理3D地图导航、语音交互等大型应用时反应是否足够流畅,而GPU则决定了车机屏幕的分辨率是否足够清晰,以及各种动画效果的显示是否流畅。如果GPU性能较弱,高分辨率的图像、复杂的动画都无法流畅渲染。一旦每秒渲染的画面低于24帧,人们就会觉得车机“卡成PPT”。
此外,高通作为移动芯片领域的老大,其820A SoC芯片还有一个明显的优势,就是内嵌了4G LTE调制解调器,直接可以实现4G通信,而选择其他芯片玩家的产品,则还得外挂一颗通信芯片。
此前几十年,汽车芯片市场,基本都被恩智浦、德州仪器、瑞萨半导体等汽车芯片巨头所垄断,外来者鲜有机会可以入局。但到了2020年这个节点,高通820A终于在汽车产业上撕开一个缺口,也意味着传统玩家们在这领域,已经被高通杀到了家门口。
骁龙820A在车机芯片市场玩得风生水起,可这一市场此前一直都是德州仪器、恩智浦、瑞萨电子这些传统厂商的天下,为什么高通突然在2020年火起来了呢?
汽车作为工业产品,设计生命周期一般都在10年以上,与消费电子类产品相比显然更长,同时对稳定性的要求也就更高。因此,传统汽车芯片企业从研发和成本两个方面考量,决定用已经成熟的制造技术造汽车芯片,这样既能控制成本,也能让芯片的稳定性更高。
也正是这种原因,上述老玩家的产品在性能上才会集体败给高通,而高通820A芯片本身,也已经是多年前的产品,在手机芯片领域,已经进入了865时代。
四
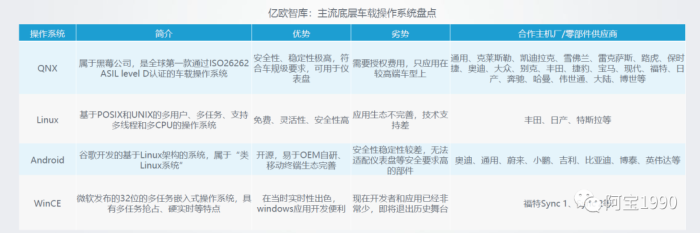
a.车载操作系统:QNX 、Linux 平分秋色,微软逐渐淘汰
操作系统,这是软件运行的底层基础,也是目前我国还未能攀越的技术高峰。PC时代的微软、移动智能手机时代的苹果和谷歌,这些企业不管是市值还是社会影响力都是顶级的存在。
他们的共同特征也为世人所熟知,那便是掌握了当下时代的操作系统主导权。现在,谁能掌控汽车操作系统,便有机会获得下一轮科技巨头圆桌会议的入场券。
汽车操作系统主要分为安全相关的车控操作系统和与用户体验相关的车载操作系统两大部分。其中,车载操作系统应用于导航、信息娱乐、蓝牙语音等。
底层车载操作系统形成 QNX、Linux、Android 三大阵营,WinCE 即将退出市场。
QNX、Linux是车载操作系统的鼻祖。
QNX 具有安全性高等优点,主要应用于仪表,但 其并非开源,因此存在开发难度大、成本高等问题。
与 QNX 相比,Linux 为免费的开 源系统,具备定制开发灵活、成本较低等特点,主要应用于信息娱乐系统。谷歌 Android 是基于 Linux 系统内核开发而来,应用生态优于 QNX、Linux,并逐渐成为新的一级。
国内企业也纷纷加入操作系统竞争市场,阿里基于 Linux 系统内核开发出 AliOS,上汽 荣威所搭载的斑马智行系统即基于 AliOS 打造。此外,鸿蒙系统(Harmony OS)同样 基于 Linux 系统内核开发。
WinCE 由微软开发,但现阶段开发者和应用已经非常少,微 软计划 2021 年 3 月终止对它的技术服务。
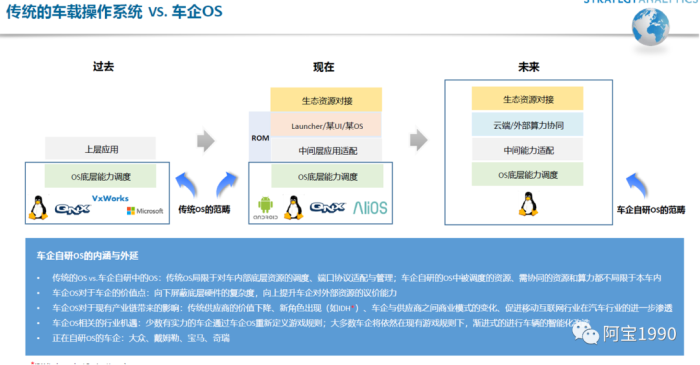
从车企角度看,绝大多数外企车厂、零部件供应商(如奔驰、宝马、博世等)和国内造车新势力(如小鹏、蔚来等)选择自建技术团队,在底层操作系统基础上进行定制化开发,形成自己独有的车载系统。部分国内主机厂(如上汽荣威)则选择和互联网公司合作,开发一定的权限,直接搭载合作伙伴所开发的车载系统。
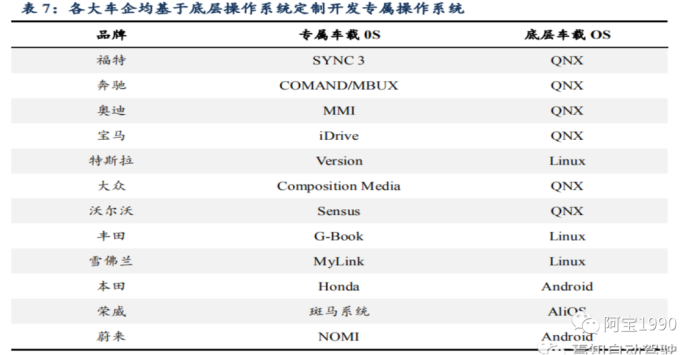
各大车企均基于底层操作系统开发其专属操作系统。
大部分车企会在底层操作系统基础之上进行定制化开发其专属的车载操作系统。
例如基于 QNX 底层操作系统的车企 有福特、奔驰、奥迪、宝马、大众、沃尔沃等,基于 Linux 底层操作系统的车企有特斯 拉、丰田、雪佛兰等。
国内能提供定制专属操作系统的上市企业包括:
中科创达、东软集团、诚迈科技、四维图新以及德赛等车机系统 Tier 1 级供应商等。
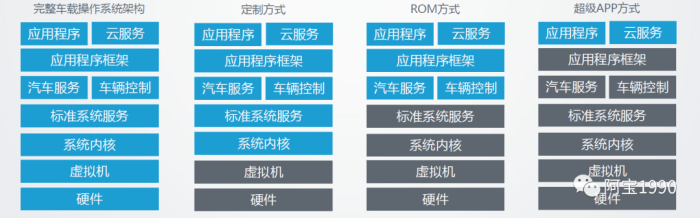
车企开发自主车载系统方式主要分为三种,标准的定制化操作系统,从系统内核到应用程序层级进行深度重构,将硬件资源进行整合优化,ROM方式,基于需求定制化汽车服务及以上层级,下层则基于Android等系统自有架构,超级APP方式,只在应用层调系统已有接口实现相关功能,其余层级则完全沿用已有系统架构。
在说说QNX的虚拟化之前,作为硬件的理解程度来说说QNX操作系统和Linux的有哪些区别。
虽然现有的操作系统有很多,从内核的角度来分类,基本可以分为三种架构,单一内核,宏内核和微内核。
单一内核结构将内核模块、驱动和用户程序都放到内核空间中,直接通过物料地址来访问内存,具有最快的访问速度和信息传递,缺点是如果用户程序出现溢出或者错误指针,可能会破坏其他程序,导致系统崩溃,代表是vxworks5.5及以前的版本。
宏内核架构将用户程序放在用户空间中,内核和驱动程序以核心形式运行,这种避免了应用程序对于内核的破坏,同时保留了较快的访问速度,Linux,Windows均属于这一类型,在嵌入式系统应用中,芯片结构更加多样化,外围接口更加复杂,驱动程序一般都需要自己开发,在宏内核架构中,如果某个驱动程序出现故障,这可能会导致整个系统崩溃,因此该架构需要reset命令重启操作系统,而在安全性比较高的场合,重启是不允许的,因此,车辆核心安全控制领用一般也不用此架构。
微内核是指为了提高可靠性,将操作系统分成小的模块,只有一个微内核模块在核心态运行,其他功能模块作为服务进程在用户空间运行,由于把设备驱动程序和文件系统也作为普通用户进程运行,当出现故障时,虽然模块本身崩溃,但不会使整个系统死机。微内核系统具有清晰的模块化结构,只要接口符合规范,操作系统可以很方便的添加和删除模块,系统具有很好的灵活性和扩展性。此外,微内核结构的内核非常小,一般只有几十到几百kb,只保留了一些最基本的功能,包括任务管理,任务调度,任务间通信等。
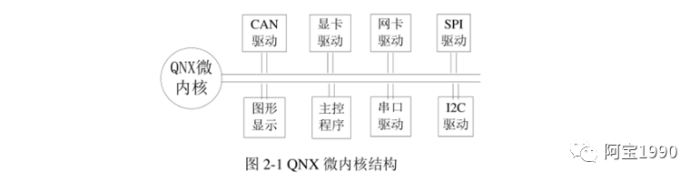
QNX是典型的微内核结构操作系统,
有一个非常小的微内核Neutrino 约为12K。内核提供了中断处理,定时器处理,线程的建立与调度等任务。另外有一个进程process manager来负责进程的建立和地址空间管理的功能, 与内核运行在内核空间。其他功能模块运行在用户空间。QNX对所有的进程均提供了内存保护, 包括文件系统, 资源管理器, 应用程序等。QNX的结构如图2-1。
为了满足不同应用的需要,在多个线程具有相同优先级并处于就绪状态时,QNX提供了三种调度方法:先进先出(First-In First-Out, FIFO) 调度、轮转(RoundRobin, RR) 调度和自适应调度。
(1)先进先出调度在先进先出的调度方式下,一个线程直到它被更高优先级的线程抢占或者运行结束,才会交出控制权。
相同优先级的任务不能打断该线程。当线程完成后,内核会去寻找处于就绪状态相同优先级的线程,如果不存在, 则寻找低优先级线程。FIFO调度本身实现了数据的互斥, 在线程运行的时间内其他相同优先级线程无法进行资源抢占。
(2)时间片轮转调度在时间片轮转(RR)调度下,一个线程放弃内核有三种情况
:运行结束,被更高级优先级抢占或者消耗完自己的时间片。时间片是线程运行的最小时间单元,由操作系统预先设定。当时间片用完时,该线程自动交出控制权, 之后内核会按照和FIFO相同的方式搜索下一个工作线程。
轮转调度可以防止某一个任务连续占用太多的资源,而导致其他线程信息得不到及时处理。缺点是轮转调度会增大由于任务切换而导致的开销。
(3)自适应调度自适应调度是一种可实现自我优先级调整的调度方式。
正在运行的线程放弃CPU的情况与轮转调度相同。当线程用完自己的时间片后,如果没有高优先级或者同优先级的任务抢占,其优先级减1,即优先级衰减。当优先级衰减后,即使再次用完时间片,其优先级不会发生变化。当其被更高优先级抢占后,恢复至原来的优先级。
自适应调度主要应用在计算量较大的线程中,为避免频繁的数据切换,需要较高的优先级,同时为了避免太长时间占用CPU, 所以采用优先级衰减的方式来保持对其他任务的响应能力。
在QNX系统下, 消息传递的体系结构可以简单的描述为:服务器建立一个接收数据的通道,客户端连接到该通道并发送服务请求,服务器接收到请求后进行数据处理,将数据处理结果返回客户端。
为防止死锁,信息的传递是单向的,按照优先级顺序从低向高发送,两个线程不相互发送
。为防止优先级倒置现象的发生,消息传递采用客户驱动优先级机制,当某个客户端向服务器发送服务请求后,服务器优先级与客户端一致,直到服务完成之后,服务器恢复原来的优先级,当更高优先级的线程要求服务时,可以中断该线程而进行高优先级的服务,防止了低优先级线程对资源的占用。
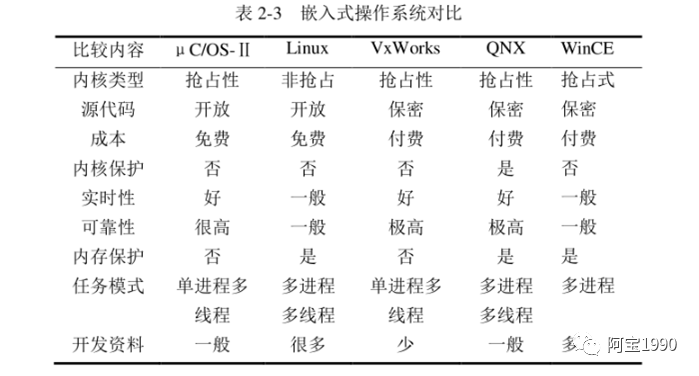
根据上述对QNX操作系统的分析, 对常用嵌入式系统做对比, 操作系统的对比资料见表2-3。
(1)uC/OS-Ⅱ不支持轮转调度,在该系统下,所有的任务被分配了不同的优先级,因此在并行任务较多的情况下,需要进行频繁的任务切换工作,会导致系统的工作效率低下。
uC/OS-Ⅱ本身是一个系统内核,仅提供了包括任务调度,时间管理在内的最基本的工作。各类驱动,文件系统,协议栈等均需要开发者完成,导致工作量增大。并且该系统并未提供良好的开发环境。
(2) Linux主要缺点在于内核是非抢占式的, 所以在对硬实时性要求比较高的场合, 需要对其内核进行一些修改。
在安全性方面, linux的驱动程序位于核心态,当驱动程序发生故障时,系统会崩溃,而这在对安全性能要求较高的场合是不能接受的,Android采用了Linux的内核,也会出现该问题。
机哥你说了QNX这么好,那域控制器一芯多屏的方案全部都采用QNX系统那就解决问题了,这里就会涉及中控操作的舒适性以及应用软件的扩展性,比如2013年的卡宴就是同构操作系统,系统稳定性好,升级不方便,而且应用不好扩展,比如中控上增加一些导航、购物、音乐等APP没有安卓系统方便。
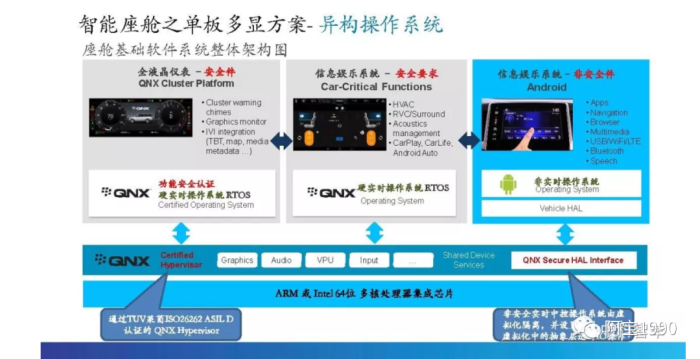
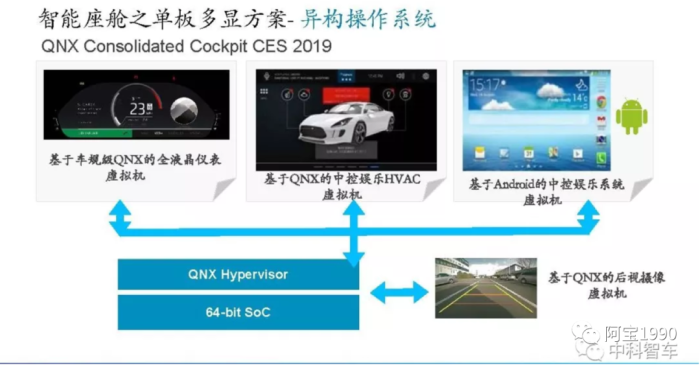
d. 域控制器操作软件介绍QNX Hypervisor
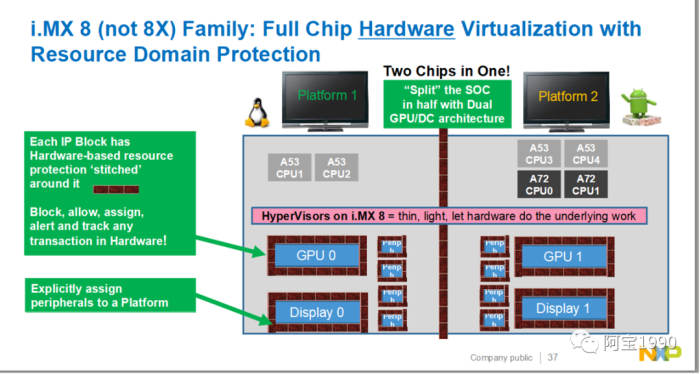
虚拟化其实是从服务器来的概念,为什么汽车也会有这个需求?两点原因:现在的中控芯片有一个趋势,集成仪表盘,降低成本。以前的仪表盘通常是用微控制器做的,图形界面也较简单。而现在的系统越来越炫,甚至需要图形处理器来参与。很自然的,这就使得中控和仪表盘合到单颗芯片内。它们跑的是不同的操作系统,虚拟化能更好的实现软件隔离。当然,有些厂商认为虚拟化还不够,需要靠物理隔离才放心,另一个趋势是中控本身需要同时支持多个屏幕,每个屏幕分属于不同的虚拟机和操作系统,这样能简化软件设计,提高软件的可靠性。
这里主要是仪表和中控,主要是从安全性,实时性几个方面导致的不同,仪表和自动驾驶系统都是实时操作系统,要把最新的车身动力信息随时体现出来,而且娱乐屏不需要。同一颗芯片跑不同的操作系统,异构操作系统可以让安卓的响应速度非常快,而且可以实现画中画的功能,而且安全性也能得到保障。
根据ISO 26262标准规定, 仪表盘的关键数据和代码与娱乐系统属于不同安全等级。因此, 虚拟机(Hypervisor) 管理的概念被引入智能座舱操作系统, 虚拟机可以允许符合车规级安全标准的QNX与Linux共同运行。
在ARM存储系统中,使用MMU实现虚拟地址到实际物理地址的映射。为何要实现这种映射?
首先就要从一个嵌入式系统的基本构成和运行方式着手。系统上电时,处理器的程序指针从0x0(或者是由0Xffff_0000处高端启动)处启动,顺序执行程序,在程序指针(PC)启动地址,属于非易失性存储器空间范围,如ROM、FLASH等。然而与上百兆的嵌入式处理器相比,FLASH、ROM等存储器响应速度慢,已成为提高系统性能的一个瓶颈。而SDRAM具有很高的响应速度,为何不使用SDRAM来执行程序呢?
为了提高系统整体速度,可以这样设想,利用FLASH、ROM对系统进行配置,把真正的应用程序下载到SDRAM中运行,这样就可以提高系统的性能。然而这种想法又遇到了另外一个问题,当ARM处理器响应异常事件时,程序指针将要跳转到一个确定的位置,假设发生了IRQ中断,PC将指向0x18(如果为高端启动,则相应指向0vxffff_0018处),而此时0x18处仍为非易失性存储器所占据的位置,则程序的执行还是有一部分要在FLASH或者ROM中来执行的。那么我们可不可以使程序完全都SDRAM中运行那?
答案是肯定的,这就引入了MMU,利用MMU,可把SDRAM的地址完全映射到0x0起始的一片连续地址空间,而把原来占据这片空间的FLASH或者ROM映射到其它不相冲突的存储空间位置。例如,FLASH的地址从0x0000_0000-0x00ff_ffff,而SDRAM的地址范围是0x3000_0000-0x31ff_ffff,则可把SDRAM地址映射为0x0000_0000-0x1fff_ffff而FLASH的地址可以映射到0x9000_0000-0x90ff_ffff(此处地址空间为空闲,未被占用)。映射完成后,如果处理器发生异常,假设依然为IRQ中断,PC指针指向0x18处的地址,而这个时候PC实际上是从位于物理地址的0x3000_0018处读取指令。通过MMU的映射,则可实现程序完全运行在SDRAM之中。
在实际的应用中,可能会把两片不连续的物理地址空间分配给SDRAM。而在操作系统中,习惯于把SDRAM的空间连续起来,方便内存管理,且应用程序申请大块的内存时,操作系统内核也可方便地分配。通过MMU可实现不连续的物理地址空间映射为连续的虚拟地址空间。
操作系统内核或者一些比较关键的代码,一般是不希望被用户应用程序所访问的。通过MMU可以控制地址空间的访问权限,从而保护这些代码不被破坏。
MMU的实现过程,实际上就是一个查表映射的过程
。建立页表(translate table)是实现MMU功能不可缺少的一步。页表是位于系统的内存中,页表的每一项对应于一个虚拟地址到物理地址的映射。每一项的长度即是一个字的长度(在ARM中,一个字的长度被定义为4字节)。页表项除完成虚拟地址到物理地址的映射功能之外,还定义了访问权限和缓冲特性等。
MMU通常是CPU的一部分,本身有少量存储空间存放从虚拟地址到物理地址的匹配表。此表称作TLB(转换旁置缓冲区)。所有数据请求都送往MMU,由MMU决定数据是在RAM内还是在大容量存储器设备内。如果数据不在存储空间内,MMU将产生页面错误中断。
2. 控制存储器存取允许。MMU关掉时,虚地址直接输出到物理地址总线。
①使用DRAM作为大容量存储器时,如果DRAM的物理地址不连续,这将给程序的编写调试造成极大不便,而适当配置MMU可将其转换成虚拟地址连续的空间。
②ARM内核的中断向量表要求放在0地址,对于ROM在0地址的情况,无法调试中断服务程序,所以在调试阶段有必要将可读写的存储器空间映射到0地址。
③系统的某些地址段是不允许被访问的,否则会产生不可预料的后果,为了避免这类错误,可以通过MMU匹配表的设置将这些地址段设为用户不可存取类型。启动程序中生成的匹配表中包含地址映射,存储页大小(1M,64K,或4K)以及是否允许存取等信息。
有了上述的MMU的概念再来了解虚拟化就比较容易了。
2、汽车芯片如何设计虚拟化(本章节是参考芯片设计内容)
虚拟化在硬件上有什么具体要求,这并没有明确定义。
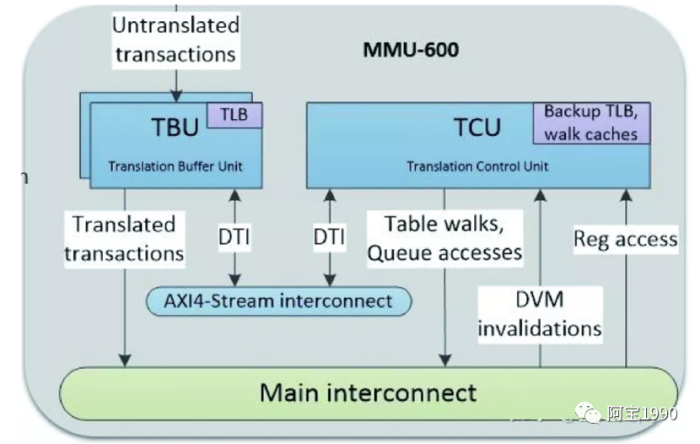
可以依靠处理器自带的二阶内存管理单元( s2MMU ), 实现软件虚拟机; 也可以在内存控制器前放一个硬件防火墙, 对访问内存的地址进行检查和过滤,不做地址重映射;还可以使用系统内存管理单元SMMU实现完整的硬件虚拟化
,这是我们要重点介绍的。
如上图黄色框所示,每个主设备和总线之间,都加了一个MMU600。为什么每个主设备后都要加?很简单,如果不加,那必然存在安全漏洞,和软件虚拟化无异。那为何不用防火墙?防火墙的的实现方法,通常是用一个片上内存来存放过滤表项。如果做到4K字节的颗粒度,那4G字节内存就需要1百万项,每项8位,总共1MB的片上内存,这是个不小的成本。另外一个原因是,防火墙方案的物理地址空间对软件是不透明的,采用系统内存管理器SMMU600对上层软件透明,更贴近虚拟化的需求。
当处理器发起一次地址虚实转换请求,内存管理单元会在内部的TLB缓存和Table Walk缓存查找最终页表项和中间表项。如果在内部缓存没找到,那就需要去系统缓存或者内存读取。在最差情况下, 每一阶的4 层中间表可能都是未命中, 4x4+4=20 , 最终会需要20 次内存读取。对于系统内存管理器,情况可能更糟。如上图所示,由于SMMU本身还需引入多级描述符来映射多个页表,最极端情况需要36次的访存才能找到最终页表项。如果所有访问都是这个延迟,显然无法接受。
Arm传统的设计是添加足够大的多级TLB缓存和table walk缓存,然后把两个主设备连到接口,进行地址较为随机的访问。可以看到,主设备的5万次访问,在经过SMMU后,产生了近5 万次未命中。这意味着访问的平均延迟等于访存延迟, 150ns 以上。另一方面, 处理器开了虚拟机后,它的随机访存效率,和未开虚拟机比,却能做到80%以上,这是为什么呢?答案很简单,处理器内部的MMU,会把中间页表的物理地址继续发到二级或者三级缓存,利用缓存来减少平均延迟。而SMMU就没有这么幸运,在Arm先前的手机处理器参考设计中,并没有系统缓存。
这种情况下,即使对于延迟不太敏感的主设备,比如图形处理器,打开虚拟化也会造成性能损失,可能高达9%,这不是一个小数目。
怎么解决这个问题?在Arm服务器以及下一代手机芯片参考设计中,会引入网状结构总线,而不是之前的crossbar结构的一致性总线。网状结构总线的好处,主要是提升了频率和带宽,并且,在提供多核一致性的同时,也可以把系统缓存交给各个主设备使用。不需要缓存的主设备还是可以和以前一样发出非缓存的的数据传输,避免额外占用缓存,引起频繁的缓存替换;同时,SMMU可以把页表和中间页表项放在缓存,从而缩短延迟。
Arm 的SMMU600 还做了一点改进, 可以把TLB 缓存贴近各个主设备做布局, 在命中的情况下, 一个时钟周期就可以完成翻译;同时, 把table walk 缓存放到另一个地方, TLB 缓存和table walk 缓存通过内部总线互联。几个主设备可以同时使用一个table walk 缓存, 减少面积,便于布线的同时,又不失效率。其结构如下图
如果我们读一下Arm 的SMMU3.x 协议, 会发现它是支持双向页表维护信息广播的, 这意味着除了缓存数据一致性外, 所有的主设备, 只要遵循SMMU3.x 协议, 可以和处理器同时使用一张页表。在辅助驾驶芯片设计时,如果需要,把重要的加速器加入同一张页表,可以避免软件页表更新操作,进一步提高异构计算的效率。不过就SMU600而言,它仅仅支持单向的广播,接了SMU600的主设备,本身的缓存和页表操作并不能广播到处理器,反过来是可以的。
对于当前的汽车芯片,如果没有系统缓存,那如何减少设备虚拟化延迟呢?办法也是有的。汽车的虚拟机应用较为特殊, 目前8 个虚拟机足够应付所有的分屏和多系统需求, 并且一旦分配,运行阶段无需反复删除和生成。
我们完全可以利用这点,把二阶段的SMMU页表变大,比如1GB,固定分配给某个虚拟机。这样,设备在进行二阶段地址映射时,只需少数几项TLB表项,就可以做到一直命中,极大降低延迟。需要注意的是,一旦把二阶映射的物理空间分配给某设备,就不能再收回并分给其他设备。不然,多次回收后,就会出现物理地址离散化,无法找到连续的大物理地址了。
SMMU接受的是从主设备发过来的物理地址,那它是怎么来区分虚拟机呢?靠的是同样从主设备发送过来的vmid/streamid 。如果主设备本身并不支持虚拟化, 那就需要对它进行时分复用, 让软件来写入vmid/streamid 。当然, 这个软件必须运行在hypervisor 或者是securemonitor,不然会有安全漏洞。具体的做法,是在虚拟机切换的时候,hypervisor修改寄存器化的vmid/streamid,提供输入给SMMU即可。如果访问时的id和预设的不符,SMMU会报异常给hypervisor。
如果主设备要实现硬件的方式支持虚拟化,那本身需要根据多组寄存器设置,主动发出不同的vmid/streamid 。为了对软件兼容, 可以把不同组按照4KB 边界分开, 这样在二阶地址映射时,可以让相同的实地址访问不同组的寄存器,而对驱动透明。同时,对于内部的资源也要做区分, 不能让数据互相影响。如果用到缓存, 那缓存还必须对vmid 敏感, 相同地址不同vmid的情况,必须识别为未命中。
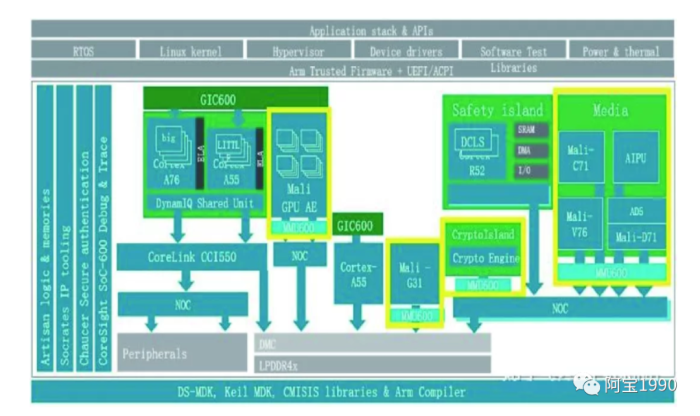
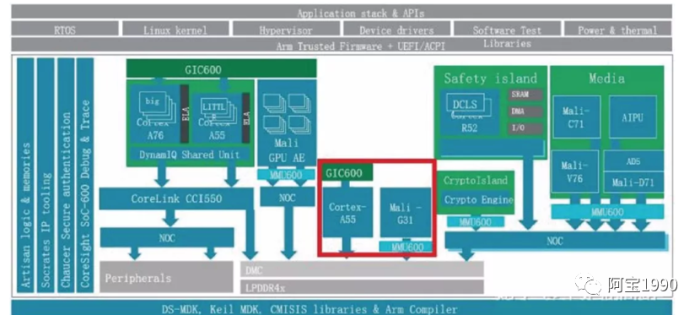
前面说到,有些厂商认为虚拟化还不够,有些场景要物理隔离。虚拟化的时候,硬件资源还是共享的,只不过对软件是透明。这样其实并不能完全防止硬件的冲突和保证优先级。请注意,硬件隔离是separation , 而不是分区partition , Partition 是用MPU 来做的。在中控的系统框架图内,我们把采用物理隔离的红色部分单独列出来,如下图
此时的处理器A55和图形处理器G31,独立于作为信息娱乐域的处理器A76/A55和图形处理器G76之外,拥有自己的电源,时钟和电压。作为优化,红色部分可以和其余的处理器用一致性总线连接起来,在不作为仪表盘应用的时候,作为SMP的一部分来使用。而需要隔离的时候,用多路选择连接到NoC或者内存控制器。这样既节省了面积,又实现了隔离。
这里可以看到飞思卡尔8就是硬件上的隔离,保障了安全性
Hypervisor 允许多个操作系统和应用共享软件。Hypervisor(又称虚拟机监视器) 是一种运行在物理服务器和操作系统之间的中间软件层。由于智能座舱需要同步支持 QNX、Android、Linux 等多操作系统,因此在物理硬件之上需要一个虚拟化平台(Hypervisor)以支持各操作系统的运行。Hypervisors 即可协调着硬件资源的访问,也 可在各个虚拟机(VM)之间施加防护。当服务器启动并执行 Hypervisor 时,它会加载 各虚拟机客户端的操作系统,同时会分配给各虚拟机适量的内存,CPU,网络和磁盘等资源。
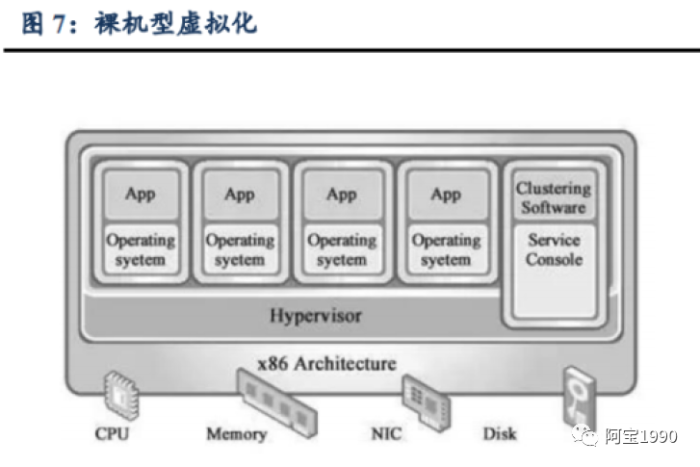
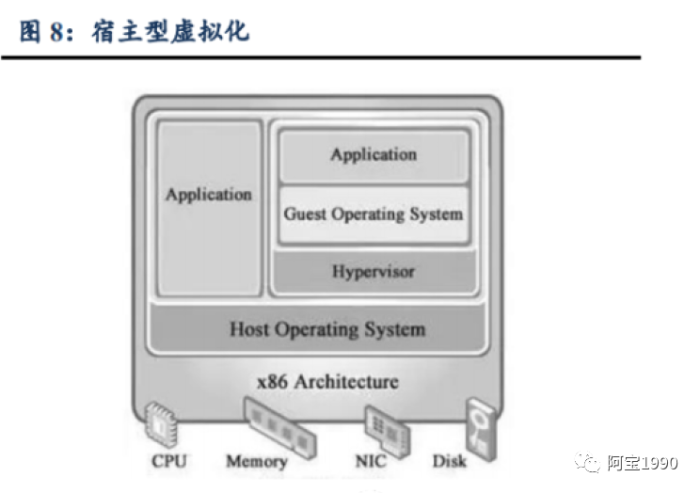
Hypervisor主要有两种类型:裸机型和宿主型。
裸机型Hypervisor最为常见, 直接安装在硬件计算资源之上, 操作系统安装并运行在Hypervisor之上。典型的裸机型有IBM的Power VM、VMware的ESX Server、Citrix的Xen Server、Microsoft的Hyper-Ⅴ以及开源的KVM等虚拟化软件。
宿主型Hypervisor(又称基于操作系统虚拟化) 将虚拟化层安装在传统的操作系统中, 虚拟化软件以应用程序进程形式运行在Windows和Linux等主机操作系统中。
典型的宿主型Hypervisor有VMware Workstation和Virtual Box。
QNX虚拟机是裸机型
这里我们车载上使用最多的QNX的虚拟机,它是裸机型虚拟机。QNX是目前唯一一个能达到Asil-D等级的操作系统(包含Hypervisor)。如果需要实现Asil-D 级别的系统, 必须把现有的软件从Linux 系统移植到QNX 。
所幸的是, QNX 也是符合Posix 标准的, 尤其是图形处理器的驱动, 移植起来会省事一些。QNX 不是所有的模块都是Asil-D 级, 移植过去的驱动, 其实是没有安全等级的。QNX 依靠Asil-D 级的核心软件模块和Hypervisor,保证99%以上的失效覆盖率。如果子模块出了问题,那只能重启子模块。

















获取更多评论