连杆编码字符识别技术研究
连杆的质量直接影响发动机动力性能。连杆编码信息追溯有利于及时追踪产品质量问题的源头。
传统发动机连杆编码主要由激光打码机在连杆侧面打码,由人工在生产系统中录入编码信息,录入效率低且易出错。因此,需要研究自动化的连杆编码字符识别技术,提高生产效率。
现有工业字符识别技术大多是针对特定的环境及结构设计相关识别方法。连杆生产过程中表面沾有切削液和铁屑,部分连杆由于切削液和铁屑太多,需要进行擦拭,这样会残留布料纤维。同时,由于连杆裂解工艺,连杆打码的表面会产生裂纹,再者,连杆编码字符在获取过程中会产生断裂及粘连,这些必然影响连杆编码字符的提取和识别。因此,需要针对连杆的生产工艺及环境,设计相应的字符识别技术。
本文提出使用多次投影技术及随机森林算法实现连杆编码字符分割及识别。首先根据连杆工件中字符位置,截取字符图像。利用均值滤波、二值化、闭运算对字符图像进行预处理。然后分别使用水平和垂直投影法进行字符行分割和列分割,并设计阈值规则实现完整、断裂和粘连字符的分割。建立随机森林算法模型,实现连杆编码字符识别。
图像预处理
连杆字符识别前需要对字符图片进行预处理,在生产现场采集的连杆字符图片如图1所示。在图像中,连杆编码字符较为清晰,同时,连杆字符表面上部的连杆结构亮度较高,这影响字符从背景中提取。由于每次字符检测,连杆都固定于工装上,因此,连杆编码字符在图片的位置较为固定,可通过字符所处坐标,从图片中将编码字符区域截取出来。

为消除噪声干扰,使用均值滤波对字符图像进行滤波,然后对滤波后的图片进行二值化,如图2所示。在二值化图像中部存在裂解工艺产生的裂纹“亮纹”,擦拭切削液残留的布料纤维等产生的“亮斑”。二值化字符中也存在细小缺损的情况,如图3中的“0”“M”“F”“1”“5”及“9”字符。对图像进行闭运算消除缺损,闭运算结果如图3所示。

字符分割
字符分割是字符识别的关键,但连杆编码字符背景较为复杂,有噪声干扰、裂纹干扰和部分连杆擦拭后残留的布料纤维干扰,这些干扰严重影响字符的分割,不利于字符识别,因此,本文根据投影法及字符位置,设计多次分割,实现字符分割。
1. 行分割
利用水平投影技术实现连杆编码字符行分割。根据字符图像的纵坐标计算每一行中“亮”的
像素数,公式如下:

式中, y 为计算的行像素值; i 和j 分别为图像的横坐标和纵坐标;w 和h 分别为图像的宽和高; x为特征函数;p 为对应坐标的像素值。计算所有连杆编码字符样本的平均水平“亮”像素数w,设为区分行的阈值。计算字符的平均高度h ,设为区分字符行的阈值。当连续行的像素数都大于,同时连续行的高度大于h时,可认为所在行区域为连杆编码字符行。
2.字符分割
根据投影法,计算已分割的各行字符的垂直投影,各行字符中间都有一条竖纹,并且在垂直投影计算结果上也可体现,其是由裂解工艺产生的裂纹,裂纹位置区域较为固定,但其在二值化图像中的大小随机,同时,裂纹更容易粘留布料的纤维,这些都会严重影响分割结果。为解决上述问题,本文根据连杆编码规则,对各行字符进行初始分割。在连杆编码中,每一行包含数个字符串,字符串间的间距较大且裂纹等干扰处于字符串间隔区域,且位置变化较小,而字符串的字符数固定,由此可以确定字符串的平均长度,而字符串间隔长度较为固定。可根据字符串和间隔长度确定各个字符串的位置,提取出各个字符串,而消除裂纹等干扰。第一行中包含两个字符串,分别是“TR20M” 和“F”, 计算所有样本中的d 11 及d 12,并计算出所有d 11 和d 12 的平均值D 11和D 12,利用结合垂直投影计算结果及字符宽度阈值  (wm 为字符平均宽度),确定第一个字符的起始横坐标x ,以x 为坐标起始,以
(wm 为字符平均宽度),确定第一个字符的起始横坐标x ,以x 为坐标起始,以 为长度,分割出第一个字符串,以
为长度,分割出第一个字符串,以  为横坐标起始,以
为横坐标起始,以 为长度分割第二个字符串,同理,可以分割第二行三个字符串,分割结果如图4所示。
为长度分割第二个字符串,同理,可以分割第二行三个字符串,分割结果如图4所示。

上述字符初始分割方法的关键是确定每一行第一个字符,但实际字符存在断裂情况,垂直投影和字符宽度阈值无法正确分割出“F”,无法确定“F”的起始坐标,从而造成字符初始分割出错,后续字符分割和识别也会出错,断裂字符分割需要满足以下公式:

式中,D F1 和D F2 分别是断裂字符的左右部分的宽度;DF3 为断裂的宽度。当满足公式(2)中的所有条件后, 可认为D F1 和D F2 两部分代表的是一个字符。以D F1 起始横坐标和D F2 终止横坐标对字符进行分割。D F2 没有限制上限主要考虑D F2 部分可能与右边字符产生粘连,在进行粘连分割前需要将D F1 和D F3 部分加入到粘连分割操作中。如果断裂字符D F1 部分与左边字符粘连,可由粘连分割法分割出来。初次分割出每一行的字符串后,可根据垂直投影及字符宽度阈值 进行二次字符分割,分割出每一个字符,并根据水平投影及字符高度阈值
进行二次字符分割,分割出每一个字符,并根据水平投影及字符高度阈值 (h m 为字符平均高度),去除每个字符上下黑边。在实际情况中, 有的字符会产生粘连,可根据字符平均宽度及字符分界区域内的垂直投影最小值确定字符间的界限,原理如图5 所示。图5 中,x 1 为粘连字符的初始横坐标,根据字符平均宽度wm,确定字符粘连的大致横坐标为x 1+w m。以此为中心,确定[x 1+w m-k ,x 2+w m+k ]范围内垂直投影波谷位置坐标x 2,即为字符分界的横坐标。以此可分割出粘连字符里的第一个字符。本文中
(h m 为字符平均高度),去除每个字符上下黑边。在实际情况中, 有的字符会产生粘连,可根据字符平均宽度及字符分界区域内的垂直投影最小值确定字符间的界限,原理如图5 所示。图5 中,x 1 为粘连字符的初始横坐标,根据字符平均宽度wm,确定字符粘连的大致横坐标为x 1+w m。以此为中心,确定[x 1+w m-k ,x 2+w m+k ]范围内垂直投影波谷位置坐标x 2,即为字符分界的横坐标。以此可分割出粘连字符里的第一个字符。本文中 。剩余字符宽度记为w x,当
。剩余字符宽度记为w x,当 时,可认为后面至少还有两个字符粘连(包括与断裂字符粘连),可继续使用上述方法进行字符分割。当
时,可认为后面至少还有两个字符粘连(包括与断裂字符粘连),可继续使用上述方法进行字符分割。当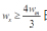 时,可认为无粘连字符,剩下的字符为最后一个字符。使用上述分割法对图4 所示字符进行完整分割,结果如图6 所示。同时,对三粘连字符进行分割,如图7 所示。由两图可以表明,本文使用的方法可以完整地分割粘连的字符。
时,可认为无粘连字符,剩下的字符为最后一个字符。使用上述分割法对图4 所示字符进行完整分割,结果如图6 所示。同时,对三粘连字符进行分割,如图7 所示。由两图可以表明,本文使用的方法可以完整地分割粘连的字符。

字符识别
1. 随机森林算法原理
字符分割完成后,需要对字符进行识别,本文使用随机森林算法实现连杆编码字符识别。随机森林算法是根据多个独立决策树的分类结果平均值,实现结果预测,单独的决策树的分类能力弱,通过集成多个决策树实现较强的分类能力。随机森林算法步骤如下:
(1)根据字符样本,有放回地随机抽取固定数量的样本,组建一定数量的字符样本子集。
( 2) 根据样本中特征数,随机提取一定数量的特征,以最优分裂点特征作为分裂节点构建决策树模型。
(3)构建多个决策树的随机森林模型。预测数据输入到随机森林模型,模型中的决策树输出类别概率,求所有决策树的概率分布,以概率最大的类别作为随机森林判别结果,分类判别表达式为:

式中, c 为类别;T 为决策树的数量; p (i,c )为类别为 c 的概率。
2. 字符识别实验
为验证连杆编码字符识别的准确性,在生产现场获取连杆编码图像样本262 张,其中随机抽取150 张编码图像样本为提取字符训练样本,共提取760 个字符训练样本,112 张图像样本用于测试,将训练样本字符归一化到40 mm×40 mm大小的图片,并输入到随机森林模型进行训练,并保存训练好的字符识别模型。
将测试样本图像经过图像预处理、字符分割及归一化后,输入到随机森林字符识别模型中,获得字符识别结果。其中,112 张连杆编码图像样本识别正确,准确率达到94.2%。其中7张图像样本中共有8个字符识别错误,如图8 所示。识别错误的字符主要是由缺损和干扰造成的, 但如图9 所示,可以正确识别的字符中也有缺损和干扰。经对比,图8 中前3个字符可以认为是字符关键部位较大的缺损造成识别结果出错。图9 中后4个字符中虽然有干扰,但是干扰主要存在字符内部,没有改变字符主体,而图8 中的后5个字符也存在干扰,并且干扰影响了字符在图像中的结构分布,从而造成识别错误。

对图像采集方法进行调整,以获取高质量的字符图像,从而解决字符关键部位缺损问题,同时优化和完善生产工艺和操作,减少对连杆字符的干扰。同时, 可根据编码意义,利用编码校验来增加字符识别错误提示,进行人工纠错,从而降低编码错误率。实验程序在CPU 为i7-6700HQ、主频为2.6 GHz、内存为16 GB 的环境下运行。连杆编码识别的完整流程平均耗时为0.566 s。
结束语
连杆编码是产品信息追溯的关键。本文针对连杆编码字符的特点,开展字符识别技术研究。首先对连杆编码字符图像进行预处理,利用水平投影法对字符图像进行行截取。针对裂解工艺产生的裂纹等干扰,根据字符分布,对图像进行初始分割,提取各行响应的字符串。然后利用垂直投影及宽度阈值分割规则,分别实现完整字符、分裂字符及粘连字符分割。利用归一化后的字符样本建立随机森林字符识别模型,模型的识别准确率为94.2%,平均耗时为0.566 s。本文提出的方法满足实际生产要求,并可通过优化和完善部分生产操作减少干扰,同时增加字符校验功能,提高字符识别的准确率。











![]()
2001-2009 Vogel Industry Media版权所有 京ICP备12020067号-15 京公网安备110102001177号


获取更多评论